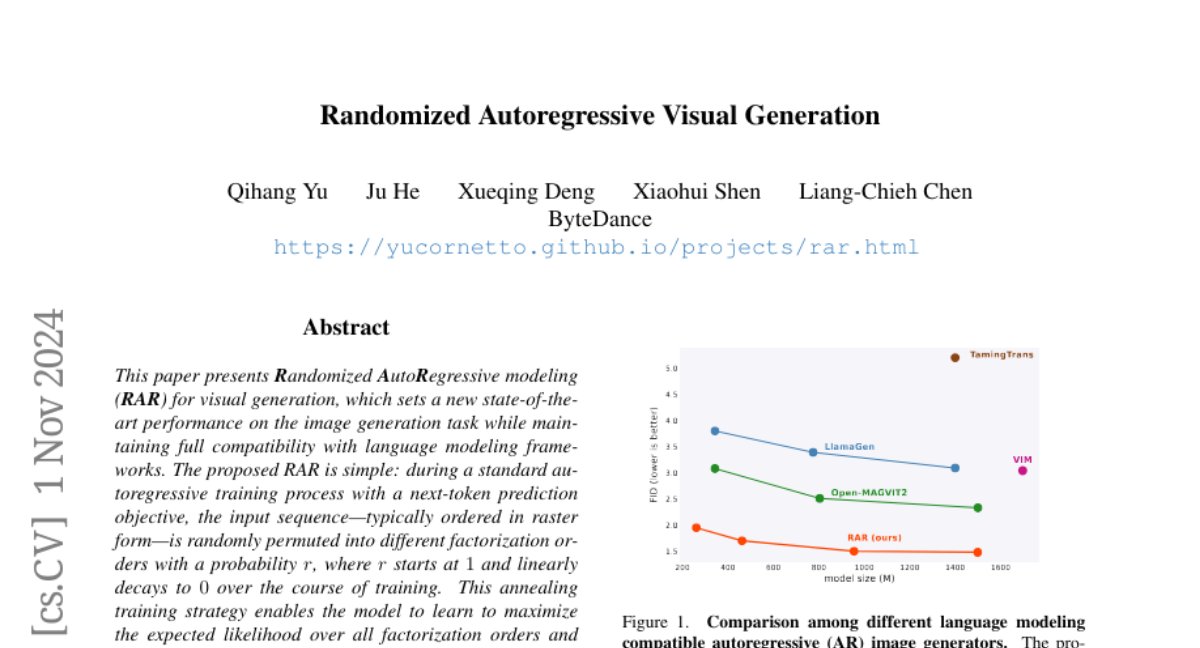
ChatDiT: Новый Подход к Генерации Изображений с Использованием Диффузионных Трансформеров
Недавние исследования arXiv:2410.15027 arXiv:2410.23775 подчеркивают присущие возможности генерации в контексте предобученных диффузионных трансформеров (DiTs), позволяя им бесперебойно адаптироваться к различным визуальным задачам с минимальными или без архитектурных модификаций. Эти возможности открываются благодаря конкатенации токенов самовнимания по нескольким входным и целевым изображениям, в сочетании с сгруппированными и замаскированными генерационными конвейерами. Исходя из этой базы, мы представляем ChatDiT - универсальную интерактивную рамку визуального генерации, которая использует предобученные диффузионные трансформеры в их исходной форме, не требуя дополнительной настройки, адаптеров или модификаций. Пользователи могут взаимодействовать с ChatDiT, чтобы создавать чередующиеся текстово-изображенческие статьи, многослойные книжки с картинками, редактировать изображения, разрабатывать производные объекты ИП или разрабатывать настройки дизайна персонажей, все это с помощью свободной естественной речи в одном или нескольких раундах общения. В своей основе ChatDiT использует систему многопользовательских агентов, состоящую из трех ключевых компонентов: агента разбора инструкций, который интерпретирует загруженные пользователем изображения и инструкции, агента планирования стратегии, который разрабатывает одноступенчатые или многоступенчатые генерационные действия, и агента исполнения, который выполняет эти действия с использованием встроенного набора инструментов диффузионных трансформеров. Мы тщательно оцениваем ChatDiT на IDEA-Bench arXiv:2412.11767, состоящем из 100 реальных дизайнерских задач и 275 случаев с разнообразными инструкциями и различным количеством входных и целевых изображений. Несмотря на свою простоту и безтренировочный подход, ChatDiT превосходит всех конкурентов, включая тех, кто специально разработан и обучен на обширных многозадачных наборах данных. Мы также выявляем ключевые ограничения предобученных DiT в нулевой адаптации к задачам. Мы публикуем весь код, агентов, результаты и промежуточные выходы, чтобы способствовать дальнейшим исследованиям на https://github.com/ali-vilab/ChatDiT.