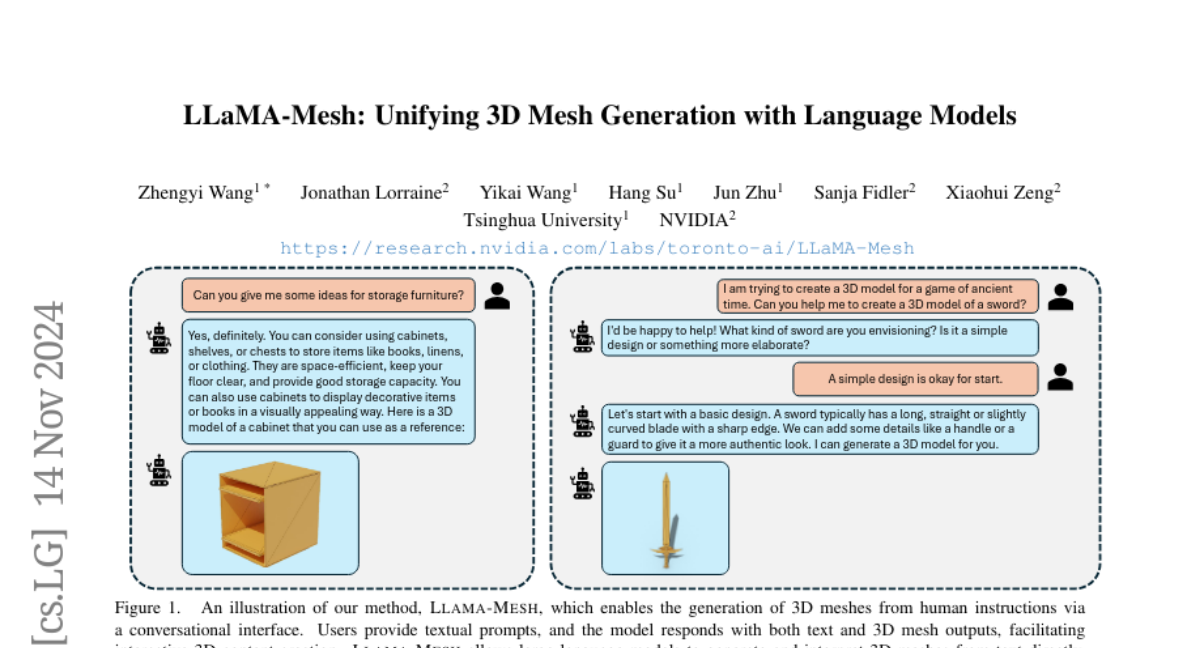
3DSRBench: Комплексный Бенчмарк Пространственного Рассуждения в 3D
3D пространственное мышление – это способность анализировать и интерпретировать позиции, ориентации и пространственные отношения объектов в 3D-пространстве. Это позволяет моделям развивать всестороннее понимание 3D-сцены, что делает их применимыми для более широкого диапазона областей, таких как автономная навигация, робототехника и дополненная/виртуальная реальность. Несмотря на то, что крупные многомодальные модели (LMMs) добились значительного прогресса в широком диапазоне задач по пониманию изображений и видео, их способности выполнять 3D пространственное мышление на различных природных изображениях изучены меньше. В этой работе мы представляем первую всестороннюю оценку 3D пространственного мышления – 3DSRBench, с 2,772 вручную аннотированными парами визуальных вопросов-ответов по 12 типам вопросов. Мы проводим тщательную и надежную оценку возможностей 3D пространственного мышления, балансируя распределение данных и применяя новую стратегию FlipEval. Чтобы дополнительно изучить надежность 3D пространственного мышления относительно 3D-углов обзора камеры, наш 3DSRBench включает два поднабора с вопросами по 3D пространственному мышлению на парных изображениях с общими и необычными углами обзора. Мы исследуем широкий спектр открытых и собственных LMM, выявляя их ограничения в различных аспектах 3D осведомленности, таких как высота, ориентация, местоположение и многократное объектное мышление, а также их ухудшенные показатели на изображениях с необычными углами обзора камеры. Наш 3DSRBench предоставляет ценные данные и insights для будущего развития LMM с сильными возможностями 3D мышления. Наша проектная страница и набор данных доступны по адресу https://3dsrbench.github.io.