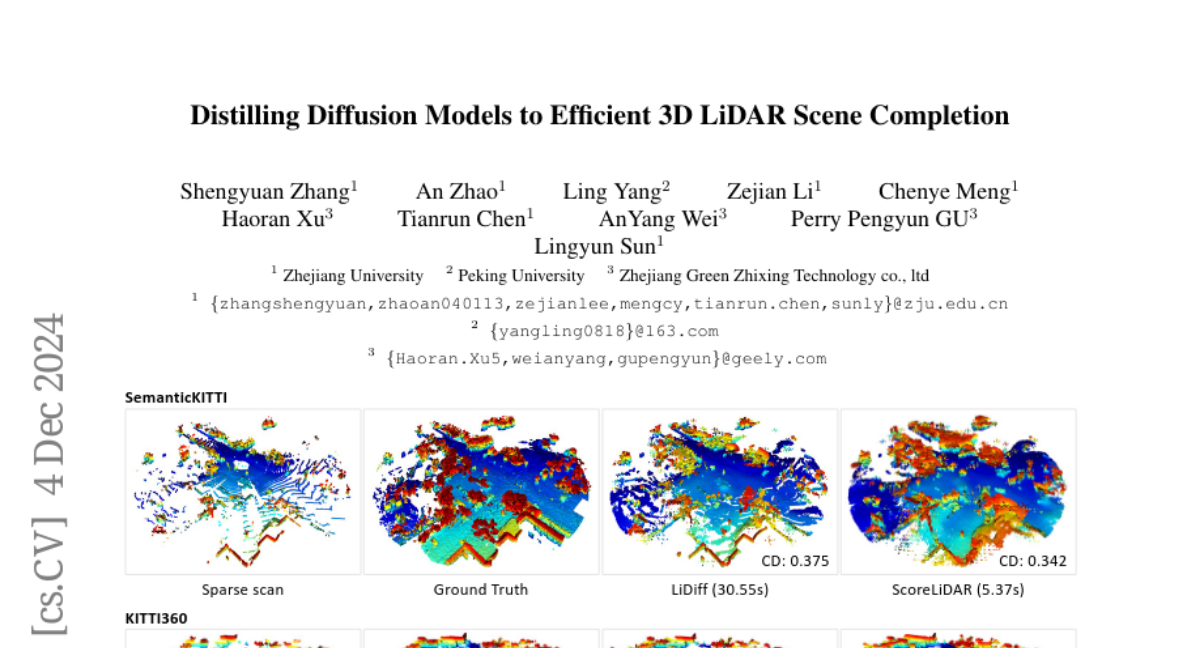
Эффективное завершение сцен LiDAR с помощью метода дистилляции ScoreLiDAR
Модели диффузии были применены для завершения сцен 3D LiDAR благодаря их высокой стабильности обучения и качеству завершения. Однако медленная скорость выборки ограничивает практическое применение моделей завершения сцен на основе диффузии, поскольку автономным транспортным средствам требуется эффективное восприятие окружающей среды. В этой статье предлагается новый метод дистилляции, адаптированный для моделей завершения сцен 3D LiDAR, названный ScoreLiDAR, который достигает эффективного и качественного завершения сцен. ScoreLiDAR позволяет дистиллированной модели выбирать значительно меньше шагов после дистилляции. Для улучшения качества завершения мы также вводим новую Структурную Потерю, которая побуждает дистиллированную модель захватывать геометрическую структуру сцены 3D LiDAR. Потеря содержит терм, ограничивающий целостную структуру сцены, и точечный терм, ограничивающий ключевые контрольные точки и их относительную конфигурацию. Обширные эксперименты показывают, что ScoreLiDAR значительно ускоряет время завершения с 30,55 до 5,37 секунд на кадр (>5 раз) на SemanticKITTI и достигает превосходной производительности по сравнению с современными моделями завершения сцен 3D LiDAR. Наш код доступен по адресу https://github.com/happyw1nd/ScoreLiDAR.
