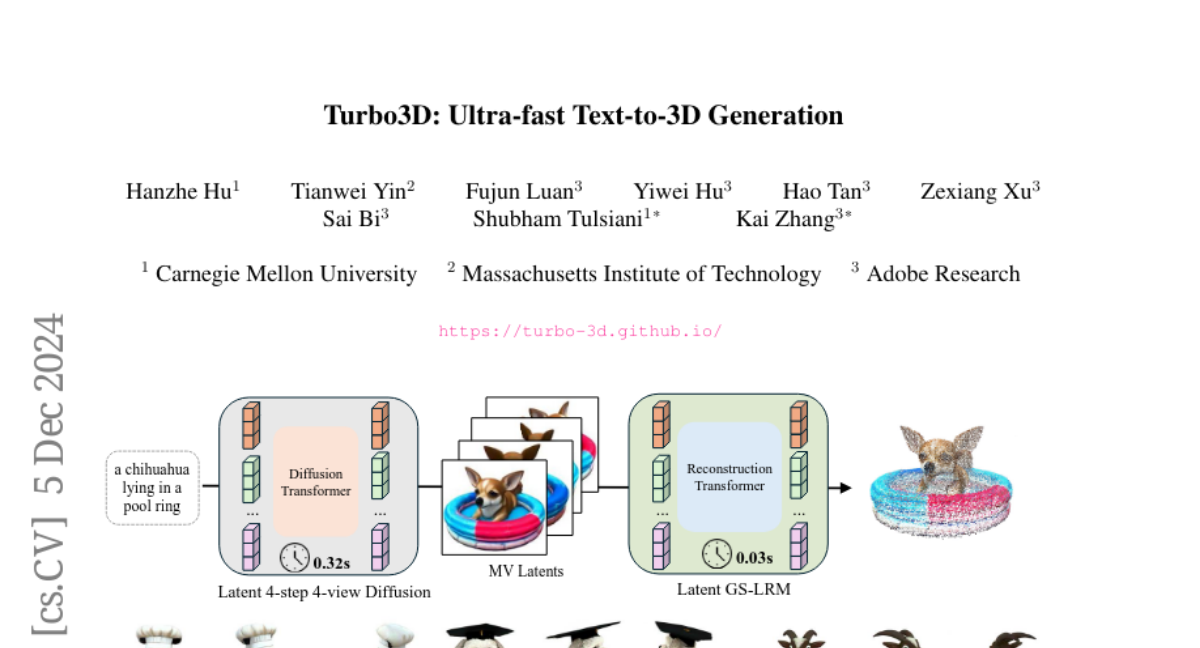
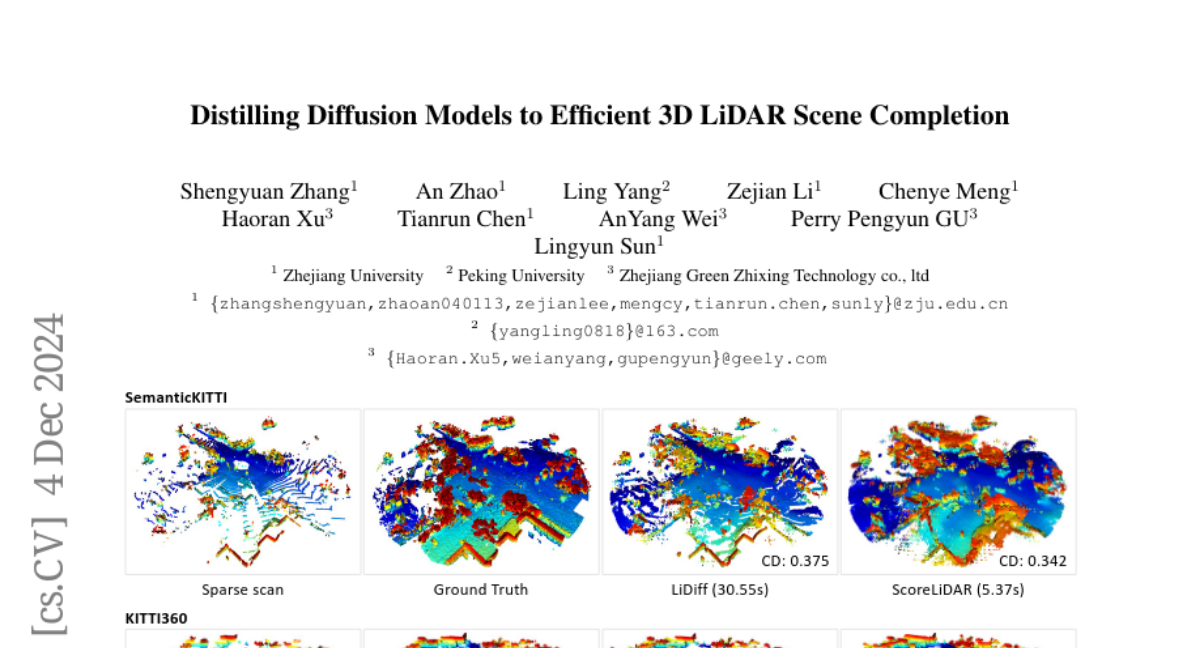
SnapGen: Эффективные архитектуры и обучение высококачественных моделей текст-в-изображение для мобильных устройств
Существующие модели диффузии текст-в-изображение (T2I) сталкиваются с несколькими ограничениями, включая большие размеры моделей, медленное время выполнения и низкое качество генерации на мобильных устройствах. Цель этой статьи — решить все эти задачи, разработав исключительно маленькую и быструю модель T2I, которая генерирует изображения высокого разрешения и высокого качества на мобильных платформах. Мы предлагаем несколько методов для достижения этой цели. Во-первых, мы систематически рассматриваем выборы дизайна архитектуры сети, чтобы уменьшить параметры модели и задержку, при этом обеспечивая высокое качество генерации. Во-вторых, для дальнейшего улучшения качества генерации мы используем кросс-архитектурную дистилляцию знаний от гораздо большей модели, применяя многоуровневый подход для направления обучения нашей модели с нуля. В-третьих, мы обеспечиваем генерацию за несколько шагов, интегрируя противоречивую поддержку с дистилляцией знаний. Впервые наша модель SnapGen демонстрирует генерацию изображений размером 1024x1024 пикселя на мобильном устройстве за примерно 1.4 секунды. На ImageNet-1K наша модель с всего 372M параметрами достигает FID 2.06 для генерации 256x256 пикселей. На бенчмарках T2I (т.е. GenEval и DPG-Bench) наша модель с всего 379M параметрами превосходит крупномасштабные модели с миллиардами параметров при значительно более мелком размере (например, в 7 раз меньше, чем SDXL, в 14 раз меньше, чем IF-XL).