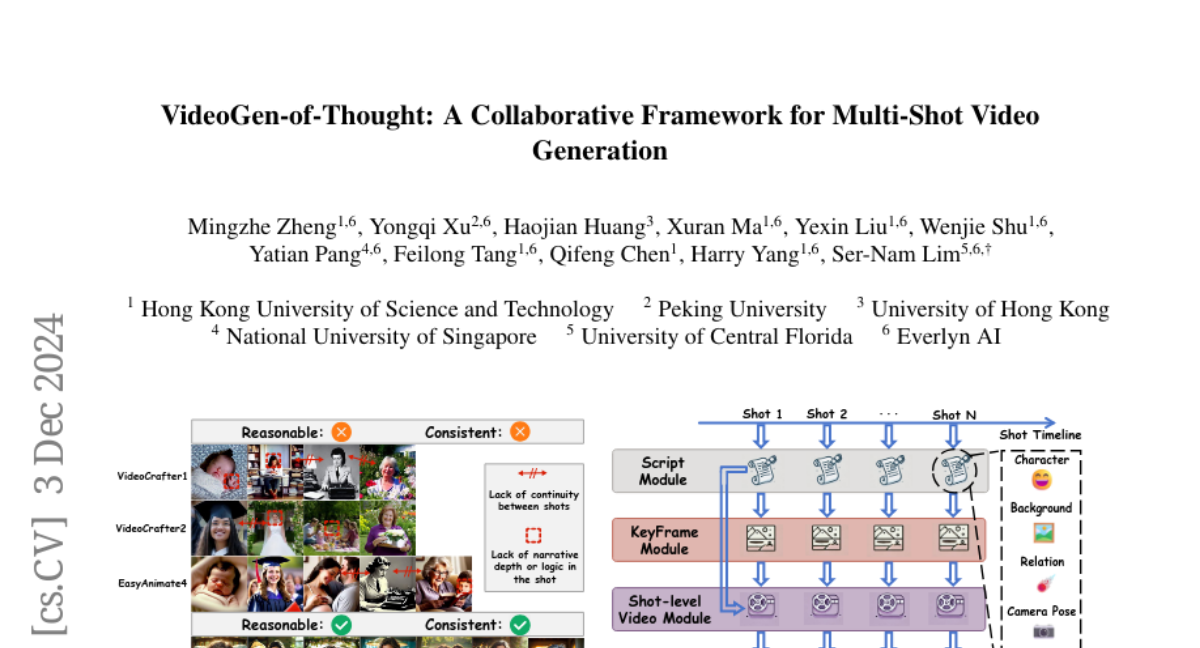
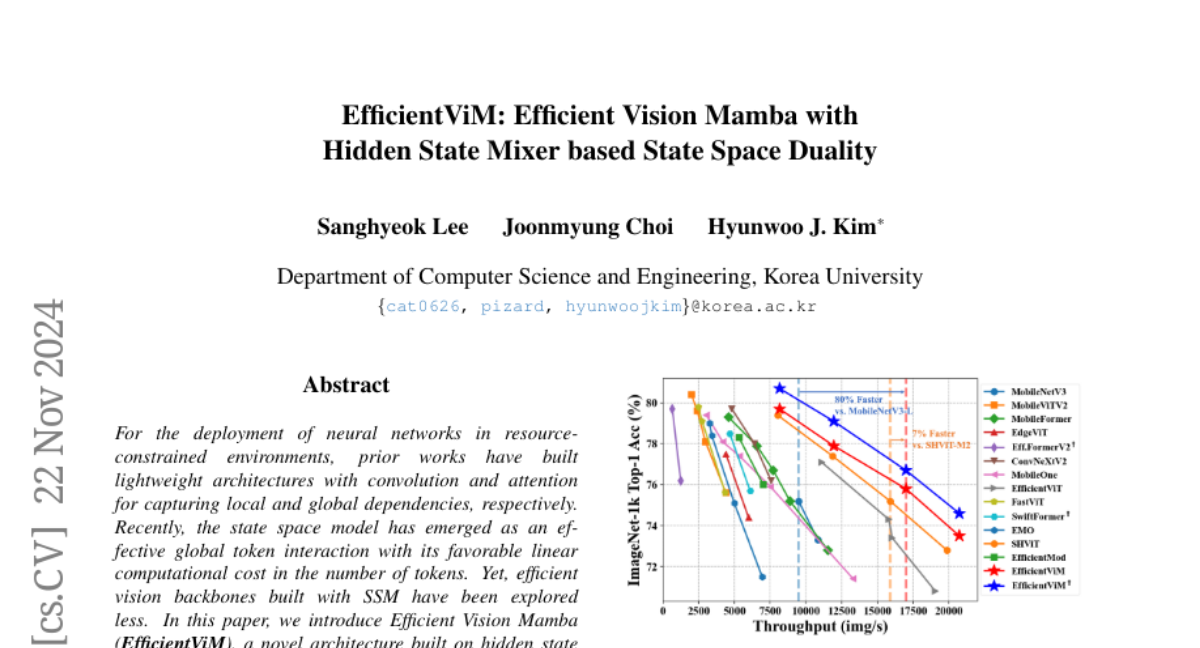
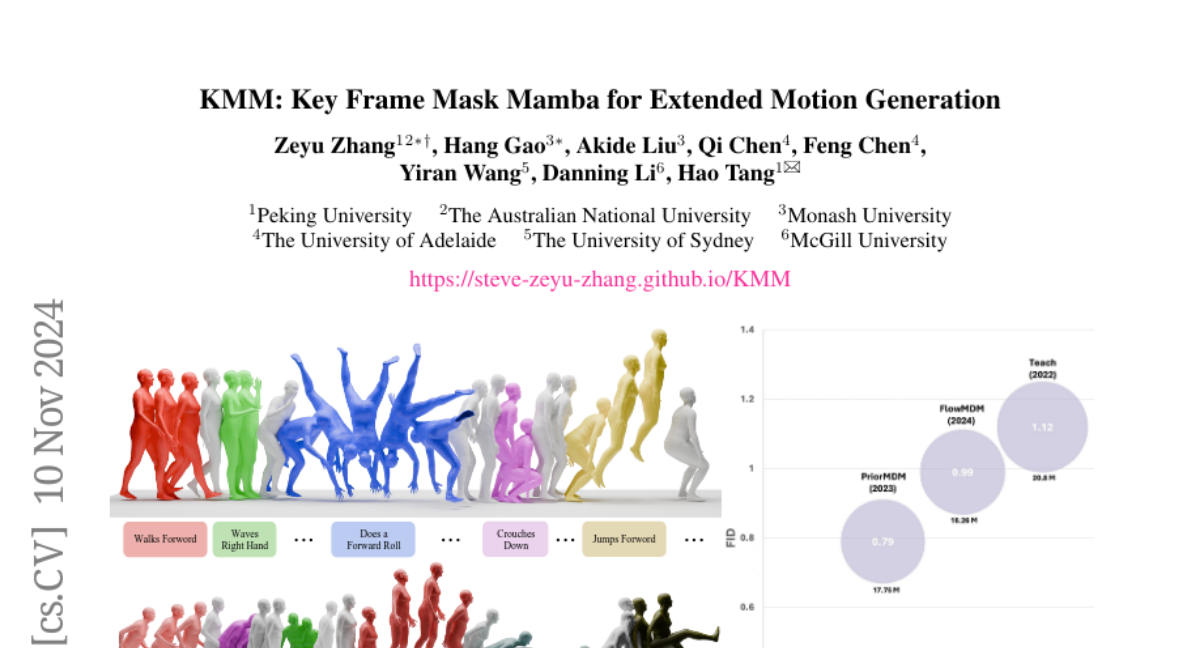
VidTok: Современный видеотокенизатор для генерации и понимания видео
Кодирование видеоконтента в компактные латентные токены стало фундаментальным шагом в генерации и понимании видео, что обусловлено необходимостью устранения присущей избыточности в представлениях на уровне пикселей. В результате растет спрос на высокоэффективные, открытые видео-токенизаторы по мере того, как исследования, ориентированные на видео, приобретают популярность. Мы представляем VidTok, универсальный видео токенизатор, который демонстрирует передовые показатели как в непрерывной, так и в дискретной токенизации. VidTok включает в себя несколько ключевых усовершенствований по сравнению с существующими подходами: 1) архитектура модели, такая как свертки и модули вверх/вниз; 2) для устранения нестабильности обучения и коллапса кодовой книги, обычно связанных с традиционной векторной кватизацией (VQ), мы интегрируем конечную скалярную кватизацию (FSQ) в дискретную видео токенизацию; 3) улучшенные стратегии обучения, включая двухступенчатый процесс обучения и использование сниженных частот кадров. Интегрируя эти усовершенствования, VidTok достигает значительных улучшений по сравнению с существующими методами, демонстрируя превосходную производительность по множеству метрик, включая PSNR, SSIM, LPIPS и FVD, в стандартизированных условиях оценки.