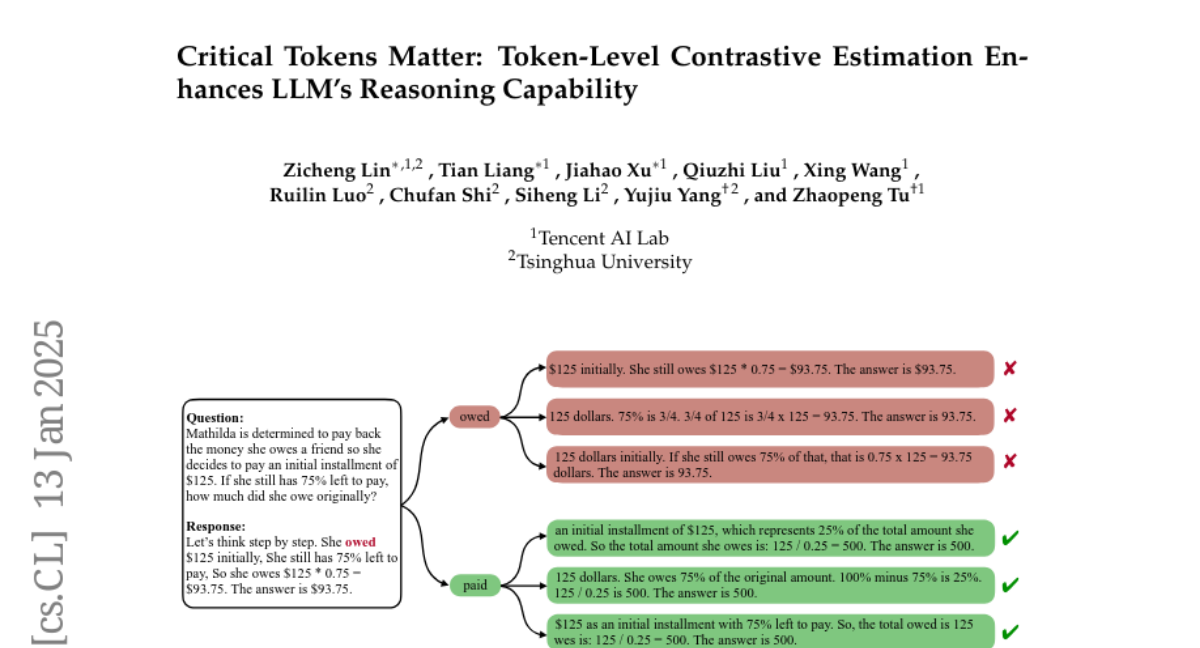
Сжатая цепочка размышлений: эффективное рассуждение через плотные представления
Декодирование с цепочкой размышлений (CoT) позволяет языковым моделям улучшать эффективность рассуждений за счет высокой задержки генерации в декодировании. В недавних предложениях были изучены варианты токенов размышлений, термин, который мы вводим и который относится к специальным токенам, используемым во время вывода, чтобы позволить дополнительным вычислениям. Предыдущие работы рассматривали токены размышлений в виде последовательностей фиксированной длины, взятых из дискретного набора встраиваний. Здесь мы предлагаем Сжатую Цепочку Размышлений (CCoT) — структуру для генерации содержательных и непрерывных токенов размышлений переменной длины. Сгенерированные токены размышлений являются сжатыми представлениями явных цепочек рассуждений, и наш метод может быть применен к стандартным языковым моделям декодеров. В ходе экспериментов мы иллюстрируем, как CCoT позволяет дополнительные рассуждения над плотными содержательными представлениями, чтобы достичь соответствующих улучшений в точности. Более того, улучшения рассуждений могут быть адаптивно модифицированы по запросу путем контроля количества сгенерированных токенов размышлений.