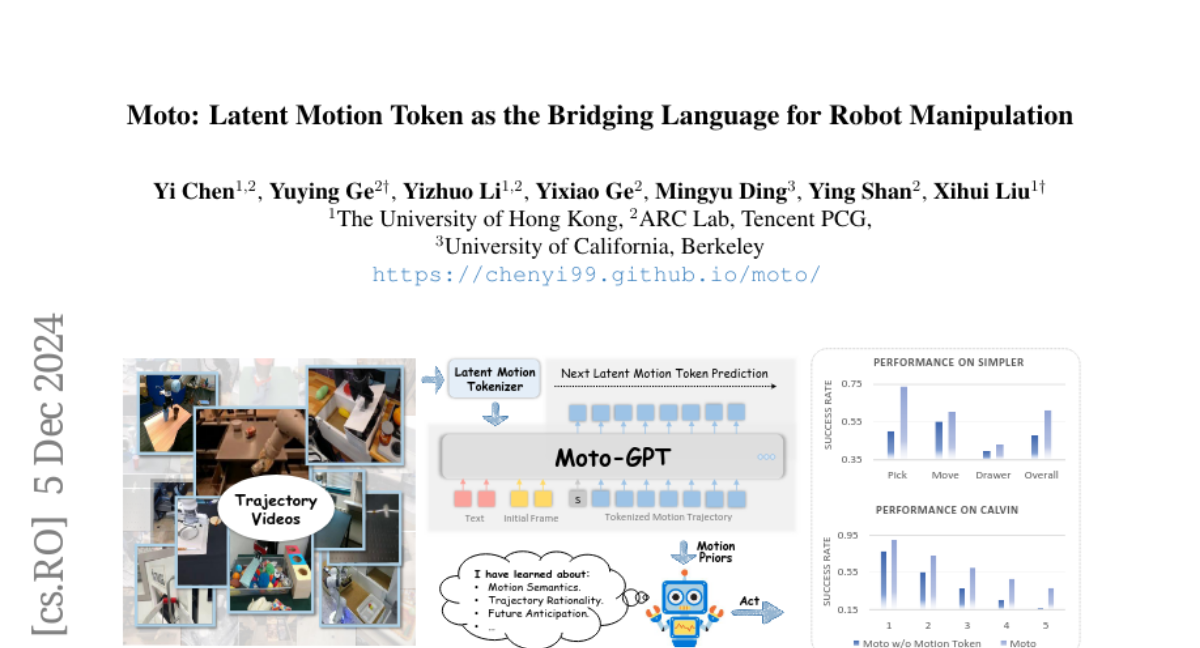
SynerGen-VL: Путь к синергетическому пониманию и генерации изображений
Удивительный успех больших языковых моделей (LLM) распространился на мультимодальную область, достигнув выдающихся результатов в понимании и генерации изображений. Недавние усилия по разработке унифицированных многомодальных больших языковых моделей (MLLM), которые интегрируют эти возможности, показали обнадеживающие результаты. Однако существующие подходы часто включают сложные дизайны в архитектуре модели или в процессе обучения, что увеличивает трудности обучения и масштабирования модели. В этой статье мы предлагаем SynerGen-VL, простую, но мощную многомодальную большую языковую модель без энкодера, способную как к пониманию, так и к генерации изображений. Чтобы решить проблемы, выявленные в существующих унифицированных многомодальных моделях без энкодера, мы вводим механизм сворачивания токенов и стратегию прогрессивного выравнивания с использованием экспертов в области зрительного восприятия, которые эффективно поддерживают понимание изображений высокого разрешения, одновременно снижая сложность обучения. После обучения на крупных смешанных данных изображений и текста с унифицированной целью предсказания следующего токена SynerGen-VL достигает или превосходит производительность существующих унифицированных MLLM без энкодера с сопоставимыми или меньшими размерами параметров и сокращает разрыв с задачами-специфическими моделями передового уровня, что подчеркивает многообещающий путь к будущим унифицированным MLLM. Наш код и модели будут опубликованы.