Moto: Латентные токены движения как связующий язык для манипуляции роботами
Современные достижения в области обработки естественного языка (NLP) продемонстрировали значительный успех благодаря использованию крупных языковых моделей (LLM), предварительно обученных на обширных корпусах данных. Эти модели показали выдающиеся результаты в различных задачах NLP с минимальной дообучением. Такой успех открывает новые возможности для робототехники, которая долгое время была ограничена высокими затратами на данные с метками действий. В связи с этим возникает вопрос: можно ли применить аналогичный подход генеративного предварительного обучения на видео данных для улучшения обучения роботов? Основной проблемой является нахождение эффективного представления для автогрессивного предварительного обучения, которое будет полезно для задач манипуляции роботами.
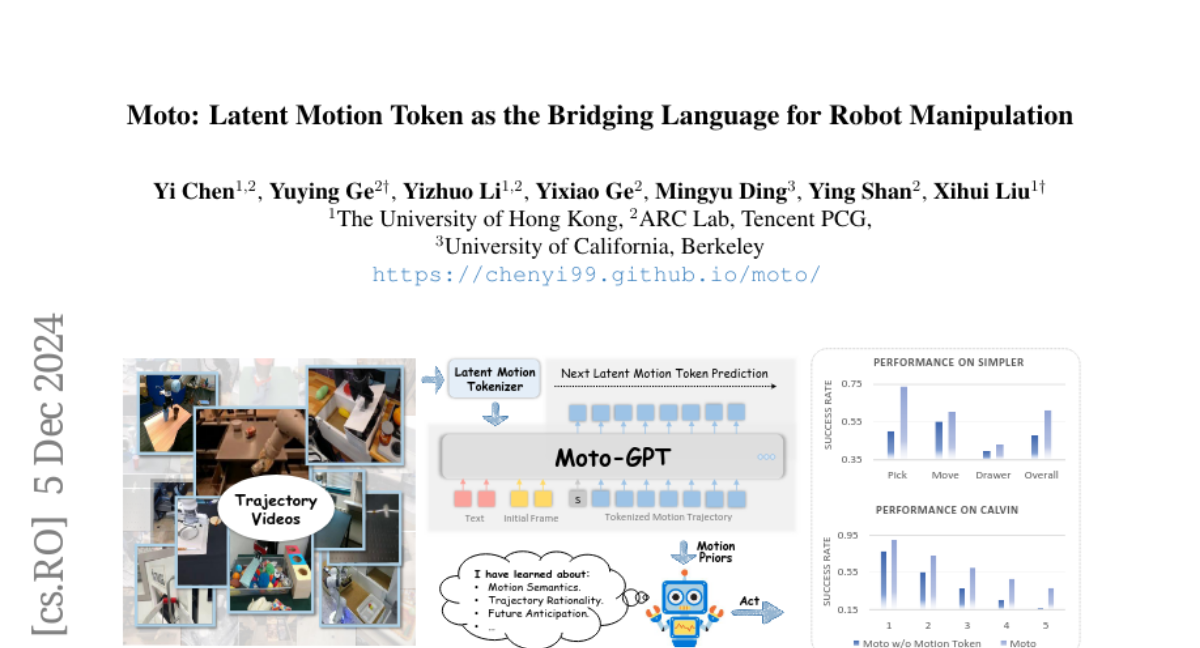
Вдохновленные тем, как люди обучаются новым навыкам, наблюдая за динамическими окружениями, мы предполагаем, что эффективное обучение роботам должно акцентировать внимание на знаниях, связанных с движением, которые тесно связаны с низкоуровневыми действиями и не зависят от аппаратного обеспечения. Это упрощает перенос изученных движений на реальные действия робота. Для этого мы представляем Moto, который преобразует видео контент в последовательности латентных токенов движения с помощью Латентного Токенизатора Движения, обучая "язык" движения в ненадзорном режиме.
Латентные токены движения
Латентные токены движения представляют собой компактные и выразительные представления движений, которые эффективно захватывают динамику между последовательными кадрами видео. Они служат связующим языком для автогрессивного предварительного обучения, позволяя модели Moto-GPT предсказывать токены движения на основе предыдущих наблюдений и текстовых инструкций. Латентный Токенизатор Движения обучается без внешнего надзора и использует архитектуру, основанную на VQ-VAE, для сжатия двух последовательных кадров видео в дискретные токены.
Архитектура токенизатора
Токенизатор использует стандартный дизайн автоэнкодера для токенизации и детокенизации. Он извлекает особенности движения из последних слоев патчей текущего кадра и предыдущего кадра, используя предобученный ViT (Vision Transformer) энкодер. После токенизации латентные токены движения используются для автогрессивного предварительного обучения Moto-GPT, который предсказывает следующие токены на основе начального кадра и текстовых инструкций.
Moto-GPT: Предварительное обучение и дообучение
Moto-GPT, основанный на архитектуре GPT, проходит предварительное обучение через предсказание токенов движения. После этого модель дообучается на данных с метками действий, что позволяет ей предсказывать действия робота на основе изученных движений. Этот процесс включает в себя добавление токенов запросов действий, которые позволяют модели генерировать реальные действия робота.
Автогрессивное предварительное обучение
Автогрессивное предварительное обучение Moto-GPT включает предсказание следующего токена движения на основе предыдущих токенов и текстовых инструкций. Это позволяет модели захватывать разнообразные визуальные знания о движении и производить правдоподобные траектории движений.
Стратегия дообучения
Во время дообучения Moto-GPT добавляются специальные токены запросов действий, которые позволяют модели генерировать реальные действия робота. Эта стратегия эффективно переносит абстрактные намерения, полученные из изученных токенов движения, в точное исполнение действий, позволяя модели использовать знания, полученные в ходе предварительного обучения.
Эксперименты и результаты
Мы провели обширные эксперименты, чтобы подтвердить эффективность Moto. Основные направления исследований включают:
-
Латентные токены движения как интерпретируемый язык движения: Эксперименты показывают, что латентные токены движения представляют компактные и выразительные представления движений, эффективно реконструируя и понимая траектории движений в видео.
-
Предварительно обученный Moto-GPT как полезный обучающийся приоритет движения: Результаты показывают, что предварительно обученный Moto-GPT достигает многообещающих результатов в предсказании правдоподобных траекторий движения и оценке рациональности траекторий робота.
-
Дообученный Moto-GPT как эффективная политика робота: Дообученный Moto-GPT демонстрирует значительное улучшение производительности по сравнению с аналогами, обученными без приоритетов движения, особенно при ограниченных данных для обучения.
Сравнение с другими моделями
Moto-GPT превосходит другие модели, такие как RT-1-X и RT-2-X, несмотря на меньший объем параметров. Это подчеркивает важность акцента на динамике движения вместо деталей визуальных кадров для обучения из видео.
Заключение и будущее
Moto открывает новые возможности для обучения роботов, используя латентные токены движения как универсальный язык для интерпретации визуальной динамики. Мы считаем, что подобный подход может быть применен к представлению человеческого движения, что позволит моделям изучать богатство знаний из видео. Будущие исследования могут сосредоточиться на масштабировании предварительного обучения на видео данных и оптимизации дообучения для улучшения производительности модели на задачах манипуляции роботами.
Таким образом, Moto представляет собой важный шаг вперед в области робототехники, предлагая новые методы для эффективного обучения на основе видео данных и улучшая способность роботов выполнять сложные манипуляции.