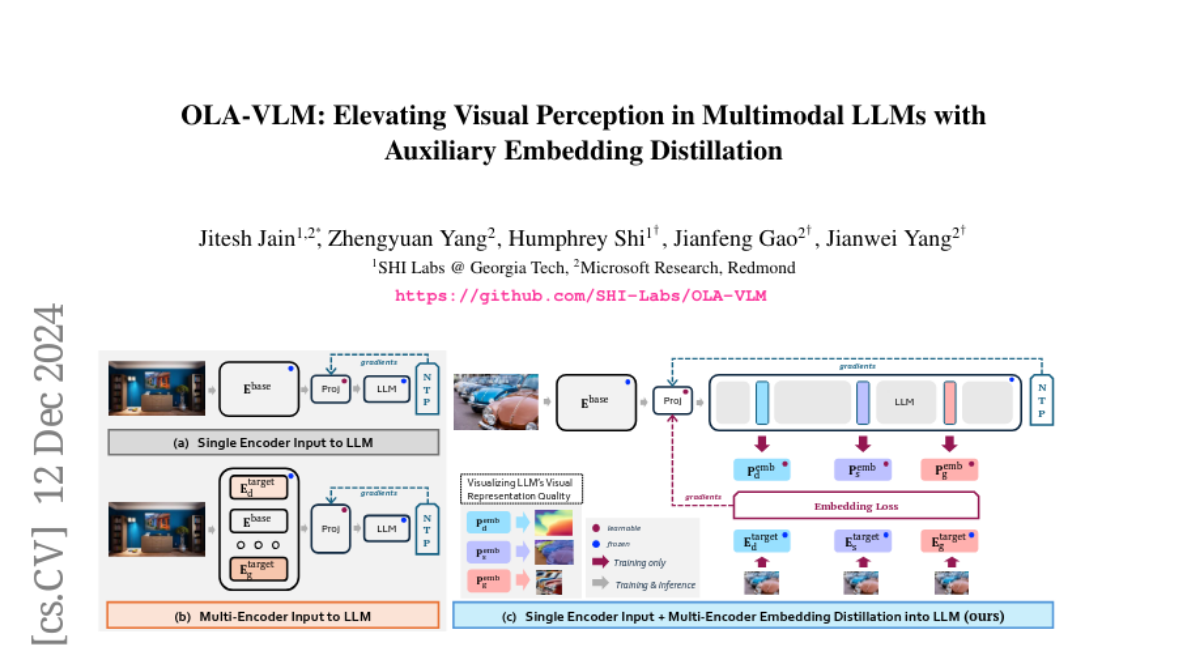
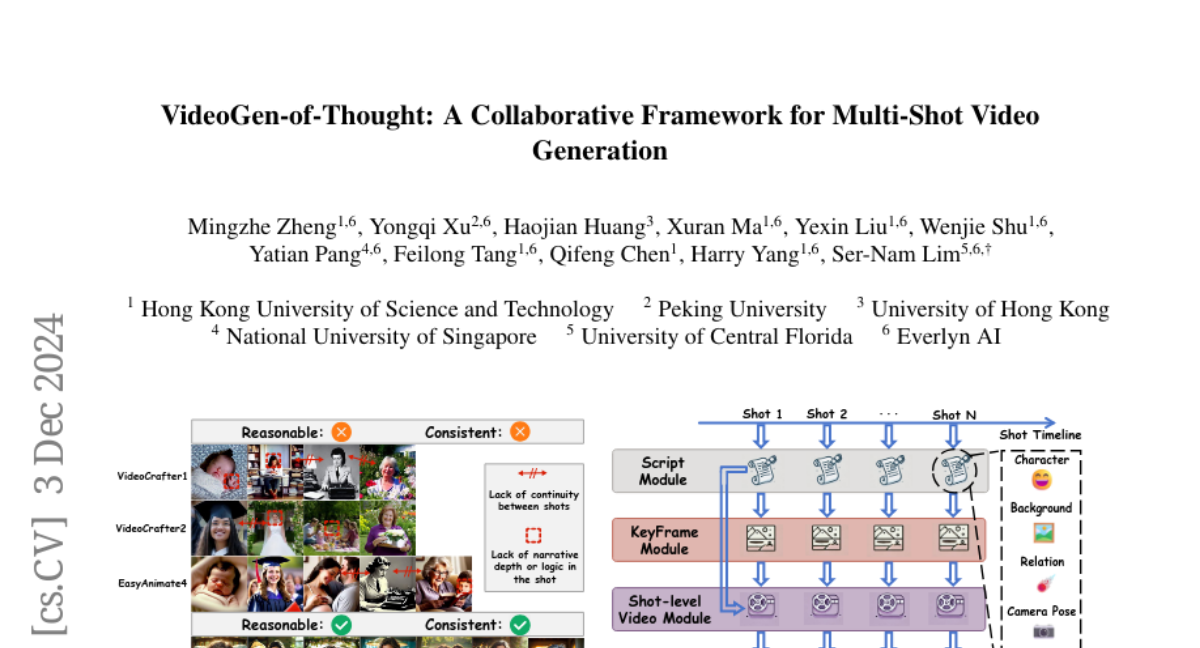
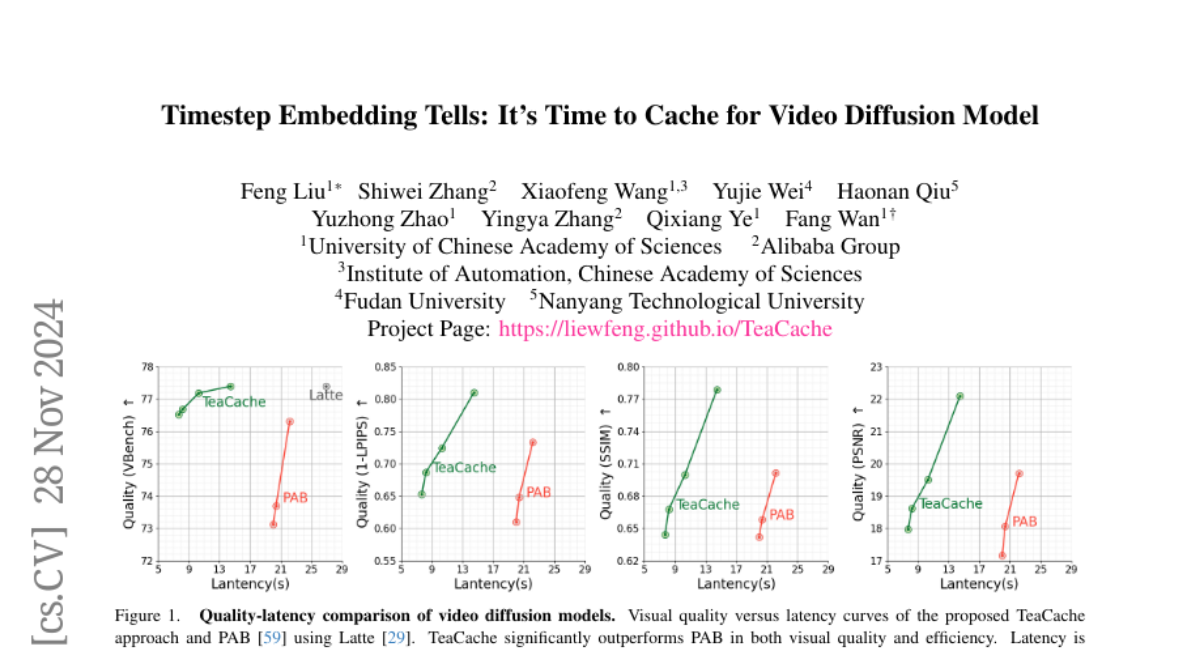
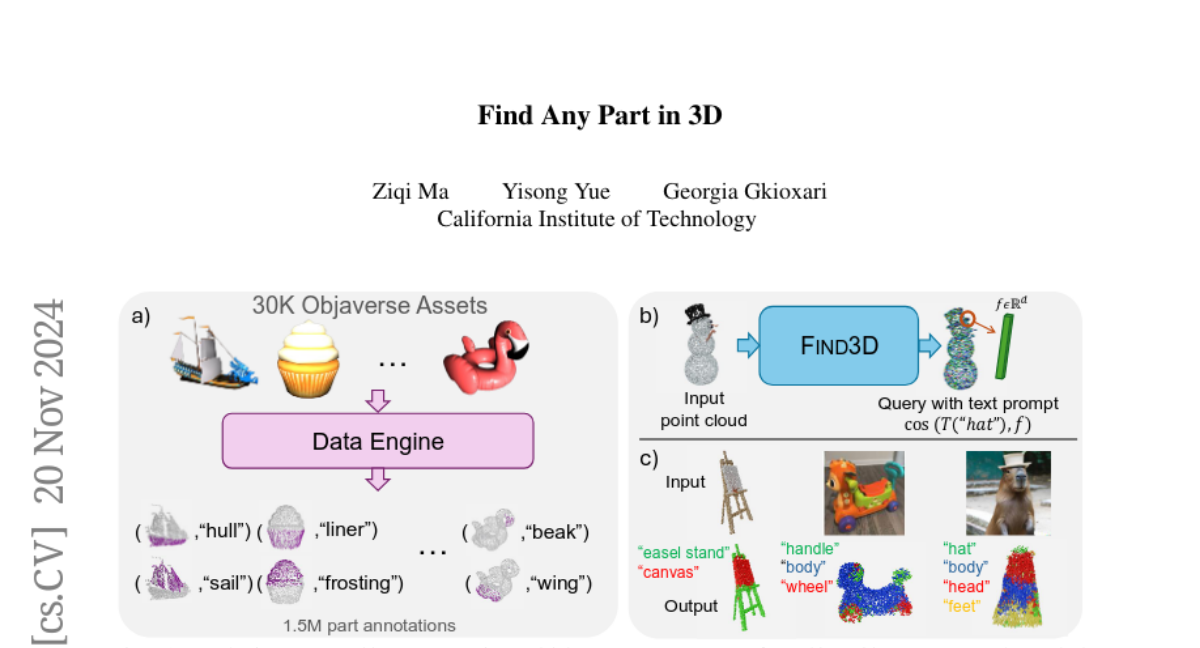
AnySat: Модель наблюдения за Землёй для любых разрешений, масштабов и модальностей
Геопространственные модели должны адаптироваться к разнообразию данных дистанционного зондирования Земли с точки зрения разрешений, масштабов и модальностей. Однако существующие подходы ожидают фиксированных входных конфигураций, что ограничивает их практическое применение. Мы предлагаем AnySat, мультимодель, основанную на архитектуре совместного встраивания предсказания (JEPA) и разрешающем пространственном кодере, что позволяет нам обучать одну модель на высокогетерогенных данных в самонаправленном режиме. Чтобы продемонстрировать преимущества этого унифицированного подхода, мы подготовили GeoPlex, сборник из 5 мультимодальных наборов данных с различными характеристиками и 11 различными датчиками. Затем мы одновременно обучаем одну мощную модель на этих разнообразных наборах данных. После донастройки мы получаем лучшие или близкие к современным достижениям результаты на наборах данных GeoPlex и 4 дополнительных для 5 задач мониторинга окружающей среды: картирование земельного покрова, идентификация видов деревьев, классификация типов культур, обнаружение изменений и сегментация наводнений. Код и модели доступны по адресу https://github.com/gastruc/AnySat.