OLA-VLM: Оптимизация визуального восприятия в многомодальных больших языковых моделях
В последние годы наблюдается стремительное развитие многомодальных больших языковых моделей (MLLM), что в значительной степени обусловлено ростом мощных языковых моделей (LLM) и доступностью больших наборов данных. Традиционная практика для улучшения визуального понимания MLLM заключается в обучении на увеличенных данных с использованием только естественного языкового надзора, что подразумевает использование задачи предсказания следующего текстового токена (NTP). Однако, как показывает практика, данная методология не всегда обеспечивает оптимальное качество визуальных представлений внутри LLM.
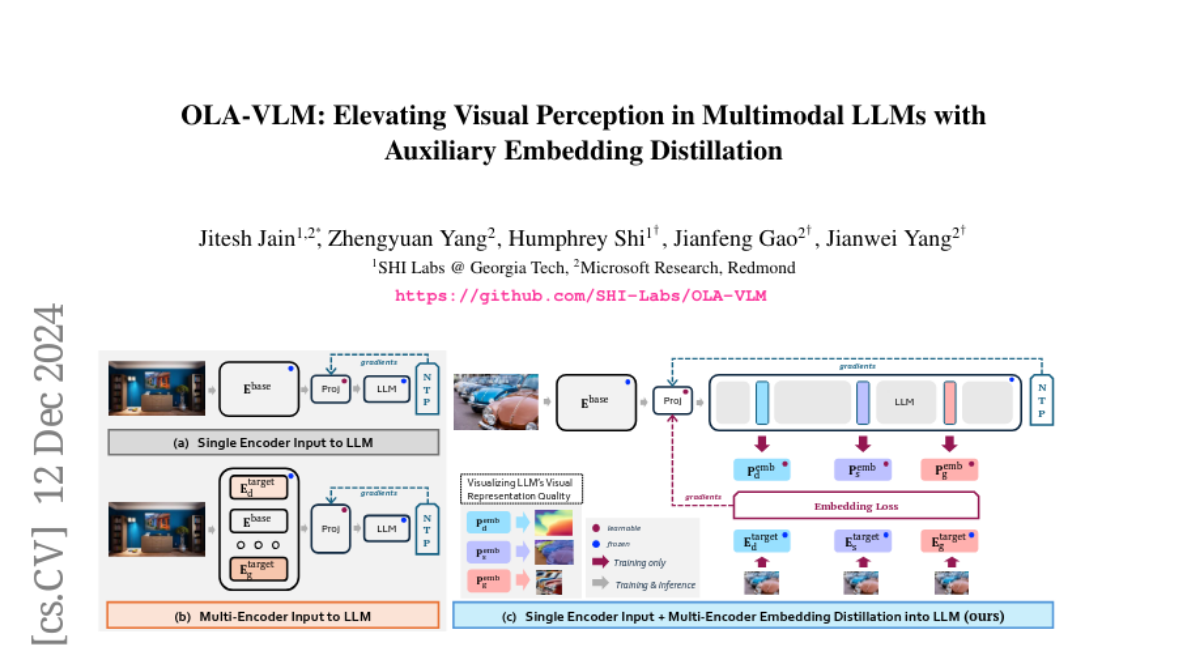
В данной статье мы предлагаем новый подход, который называется OLA-VLM, направленный на оптимизацию промежуточных представлений LLM с учетом визуальной информации. Мы утверждаем, что использование исключительно естественного языкового надзора для обучения MLLM не является оптимальным для их визуального понимания. Вместо этого мы предлагаем дистиллировать знания из набора целевых визуальных представлений в скрытые представления LLM.
Основные идеи OLA-VLM
1. Оптимизация представлений LLM
Основная идея OLA-VLM заключается в том, чтобы оптимизировать промежуточные представления LLM с помощью визуальной информации. Мы формулируем задачу обучения на этапе предобучения как совместную оптимизацию предсказательных визуальных эмбеддингов и предсказания следующего текстового токена. Это позволяет нам дистиллировать целевую визуальную информацию в промежуточные представления LLM, что, в свою очередь, улучшает качество визуальных представлений и их соответствие языковым задачам.
2. Выбор целевых визуальных представлений
Для нашей работы мы выбрали три типа задач: сегментация изображений, оценка глубины и генерация изображений. Эти задачи были выбраны из-за их фундаментального характера и хорошо изученной природы. Мы используем наборы визуальных энкодеров, обученных на этих задачах, чтобы извлекать целевые визуальные представления.
3. Применение предсказательной оптимизации эмбеддингов
В OLA-VLM мы применяем предсказательную оптимизацию эмбеддингов на определенных слоях LLM во время обучения для минимизации потерь эмбеддингов наряду с потерями от предсказания следующего токена. Это приводит к более качественным визуальным представлениям в LLM и, как следствие, к улучшению их производительности на задачах, связанных с визуальным пониманием.
Архитектура OLA-VLM
Архитектура OLA-VLM включает в себя несколько ключевых компонентов:
-
Визуальный энкодер: Мы используем один базовый визуальный энкодер во время вывода, что позволяет нам достичь лучшего соотношения между производительностью визуального понимания и эффективностью по сравнению с явной подачей нескольких визуальных входов в LLM.
-
Проектор: Проектор, который используется для выравнивания визуальных эмбеддингов с представлениями LLM, играет критическую роль в процессе дистилляции.
-
Специальные токены: Мы вводим специализированные токены, обогащенные целевой информацией, в последовательность входных данных LLM. Это способствует созданию имплицитной цепочки размышлений о визуальной информации и улучшает способность модели обрабатывать запросы, связанные с целевой информацией.
Эксперименты и результаты
1. Пробирование представлений
Перед тем как приступить к экспериментам с нашими потерями эмбеддингов, мы провели пробирование представлений на каждом слое LLM. Это позволило нам проанализировать качество представлений по сравнению с целевыми визуальными признаками. Мы обнаружили, что производительность пробирования постепенно улучшается с увеличением объема данных, что указывает на то, что LLM улучшает свои визуальные представления с увеличением объема обучающих данных.
2. Сравнение с базовыми моделями
Наши эксперименты показали, что OLA-VLM превосходит как одно-, так и многослойные базовые модели. Мы продемонстрировали, что наш подход обеспечивает улучшение производительности в среднем на 2.5% по сравнению с базовыми моделями на различных бенчмарках, с заметным улучшением на 8.7% в задаче оценки глубины.
3. Влияние объема данных на качество представлений
Мы исследовали влияние увеличения объема данных на качество визуальных представлений внутри LLM. Результаты показали, что с увеличением объема обучающих данных качество визуальных представлений внутри LLM улучшается, что подтверждает эффективность нашего подхода.
Заключение
В данной работе мы представили OLA-VLM как первый подход к дистилляции знаний из целевых визуальных энкодеров в представления LLM с помощью предсказательной оптимизации эмбеддингов. Мы подтвердили, что наш подход приводит к более сильной визуально-языковой согласованности и улучшению производительности на задачах, связанных с визуальным пониманием. Мы надеемся, что наша работа станет источником вдохновения для сообщества в разработке методов оптимизации смешанных модальностей для улучшения будущих MLLM.