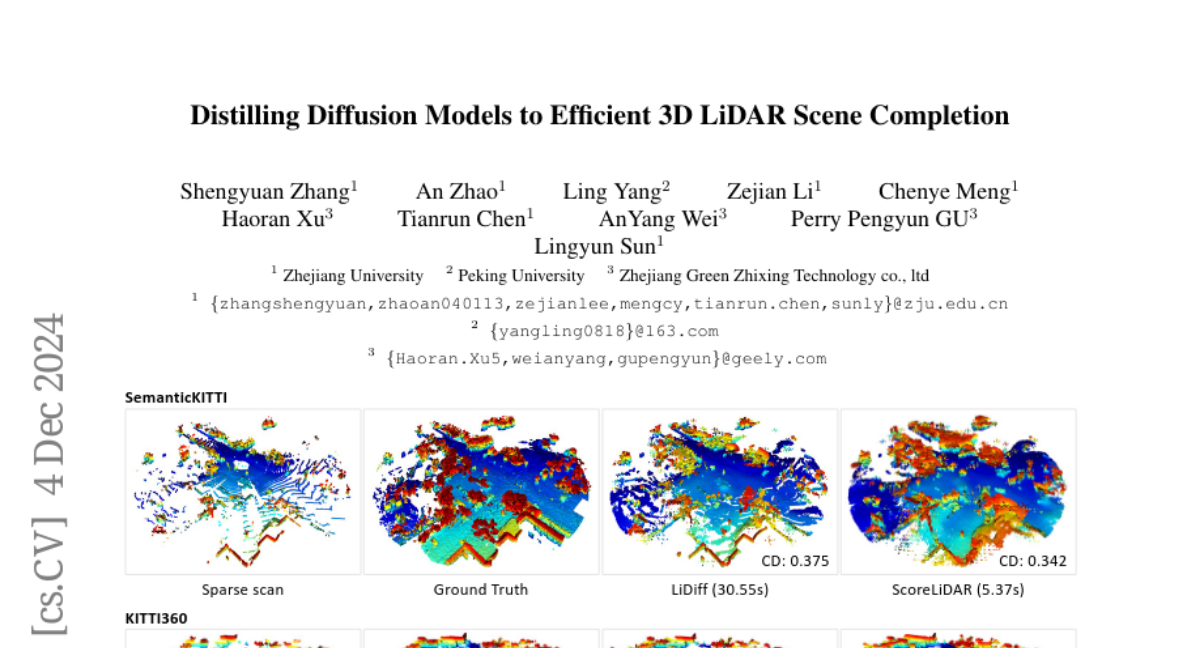
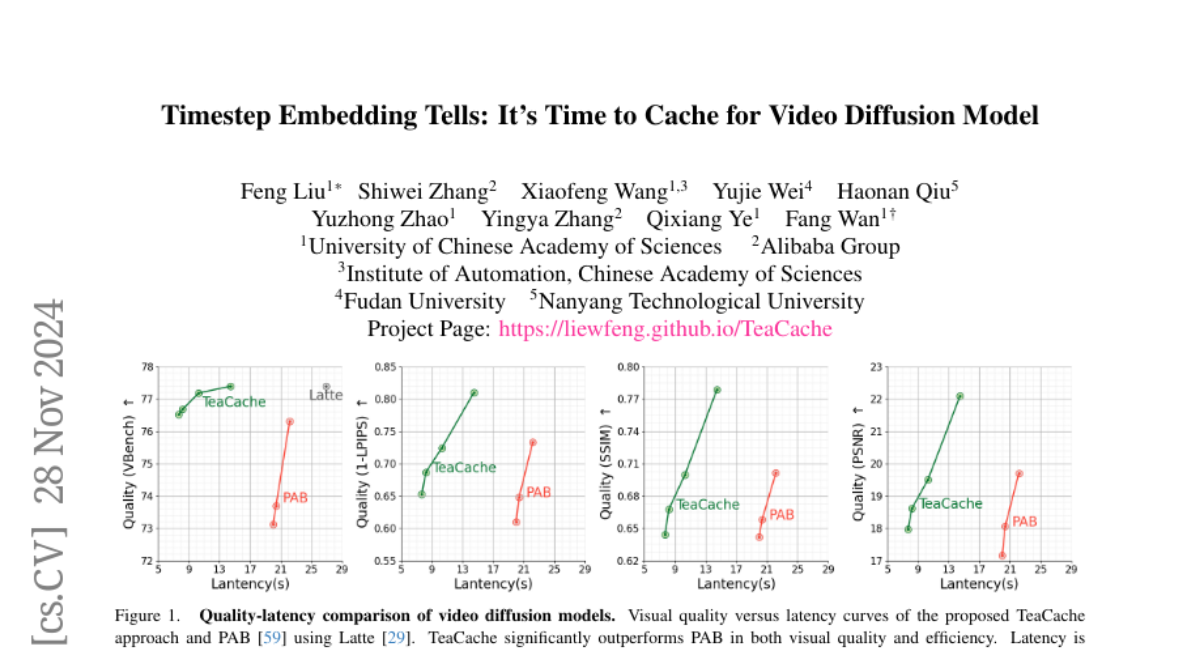
LinGen: Высококачественная генерация видео с линейной вычислительной сложностью
Генерация текста в видео улучшает создание контента, но требует высокой вычислительной мощности: вычислительная стоимость диффузионных трансформеров (DiTs) возрастает квадратично с увеличением количества пикселей. Это делает генерацию видео минутной длины крайне дорогой, ограничивая большинство существующих моделей генерацией видео только длиной 10-20 секунд. Мы предлагаем рамочную систему генерации текста в видео с линейной сложностью (LinGen), стоимость которой возрастает линейно с увеличением количества пикселей. Впервые LinGen обеспечивает генерацию видео высокого разрешения минутной длины на одном GPU без ущерба для качества. Он заменяет вычислительно доминирующий и квадратичной сложности блок, самовнимание, на блок линейной сложности, называемый MATE, который состоит из MA-ветви и TE-ветви. MA-ветвь нацелена на корреляции от короткой до длинной, комбинируя двунаправленный блок Mamba2 с нашим методом перераспределения токенов, Rotary Major Scan, и нашими токенами обзора, разработанными для генерации длинных видео. TE-ветвь — это новый блок временного внимания Swin (TEmporal Swin Attention), который фокусируется на временных корреляциях между соседними токенами и токенами средней дальности. Блок MATE решает проблему сохранения смежности Mamba и значительно улучшает согласованность сгенерированных видео. Экспериментальные результаты показывают, что LinGen превосходит DiT (с коэффициентом побед 75,6%) в качестве видео с уменьшением FLOPs (латентности) до 15 раз (11,5 раз). Более того, как автоматические метрики, так и человеческая оценка показывают, что наш LinGen-4B обеспечивает сопоставимое качество видео с моделями передового опыта (с коэффициентом побед 50,5%, 52,1%, 49,1% по сравнению с Gen-3, LumaLabs и Kling соответственно). Это открывает путь к генерации фильмов продолжительностью в час и генерации интерактивного видео в реальном времени. Мы предоставляем результаты генерации видео продолжительностью 68 секунд и больше примеров на нашем сайте проекта: https://lineargen.github.io/.