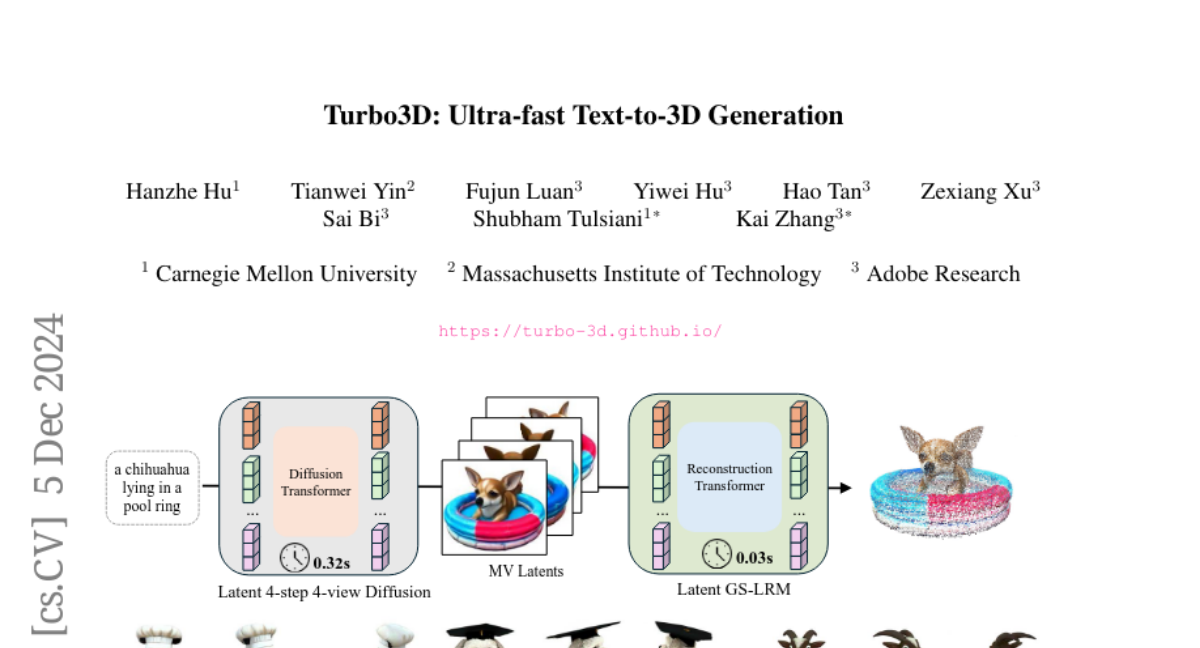
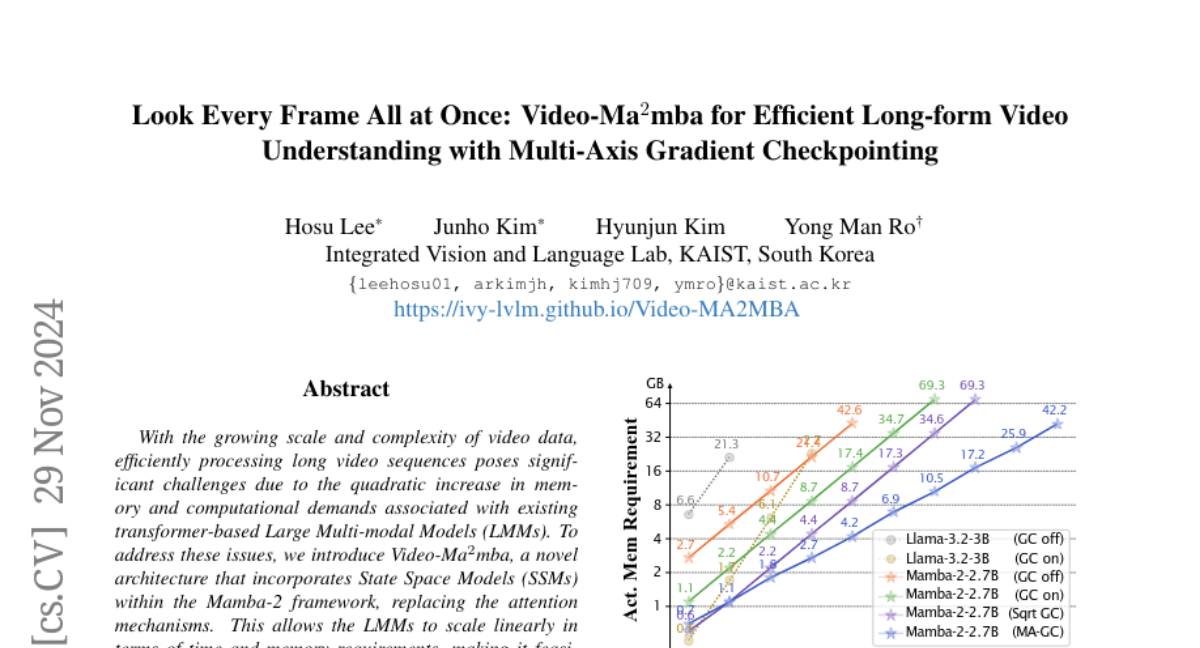
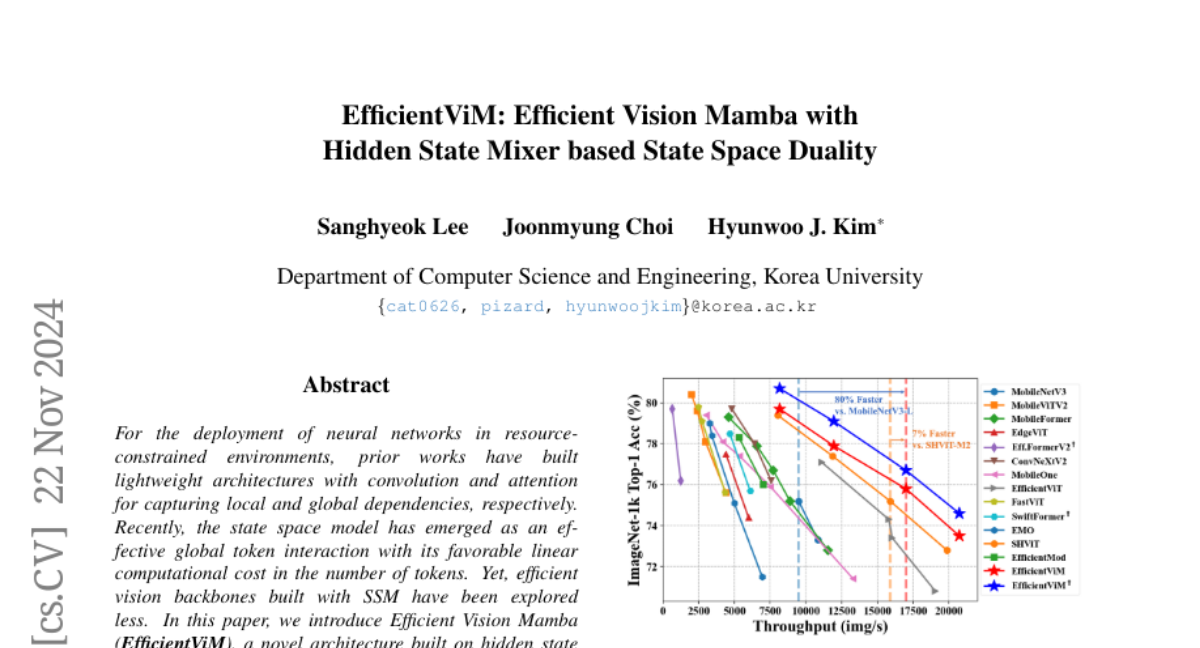
Эффективная и адаптируемая система оценки визуальных генеративных моделей: концепция Evaluation Agent
Недавние достижения в области визуальных генеративных моделей позволили создавать высококачественные изображения и видеоматериалы, открывая разнообразные возможности применения. Тем не менее, оценка этих моделей часто требует выборки сотен или тысяч изображений или видеороликов, что делает процесс вычислительно затратным, особенно для моделей на основе диффузии, обладающих медленной выборкой. Более того, существующие методы оценки полагаются на жесткие конвейеры, которые игнорируют конкретные потребности пользователей и предоставляют числовые результаты без четких объяснений. В отличие от этого, люди могут быстро сформировать впечатление о возможностях модели, наблюдая всего лишь несколько образцов. Чтобы подражать этому, мы предлагаем структуру Evaluation Agent, которая использует похожие на человеческие стратегии для эффективных, динамичных, многораундных оценок, используя всего лишь несколько образцов за раунд, при этом предлагая детализированные, адаптированные под пользователей анализы. Она предлагает четыре ключевых преимущества: 1) эффективность, 2) возможность оценки, адаптированной к разнообразным потребностям пользователей, 3) объяснимость, выходящую за рамки единичных числовых оценок, и 4) масштабируемость для различных моделей и инструментов. Эксперименты показывают, что Evaluation Agent сокращает время оценки до 10% от традиционных методов, обеспечивая при этом сопоставимые результаты. Структура Evaluation Agent полностью открыта для обеспечения продвижения исследований в области визуальных генеративных моделей и их эффективной оценки.