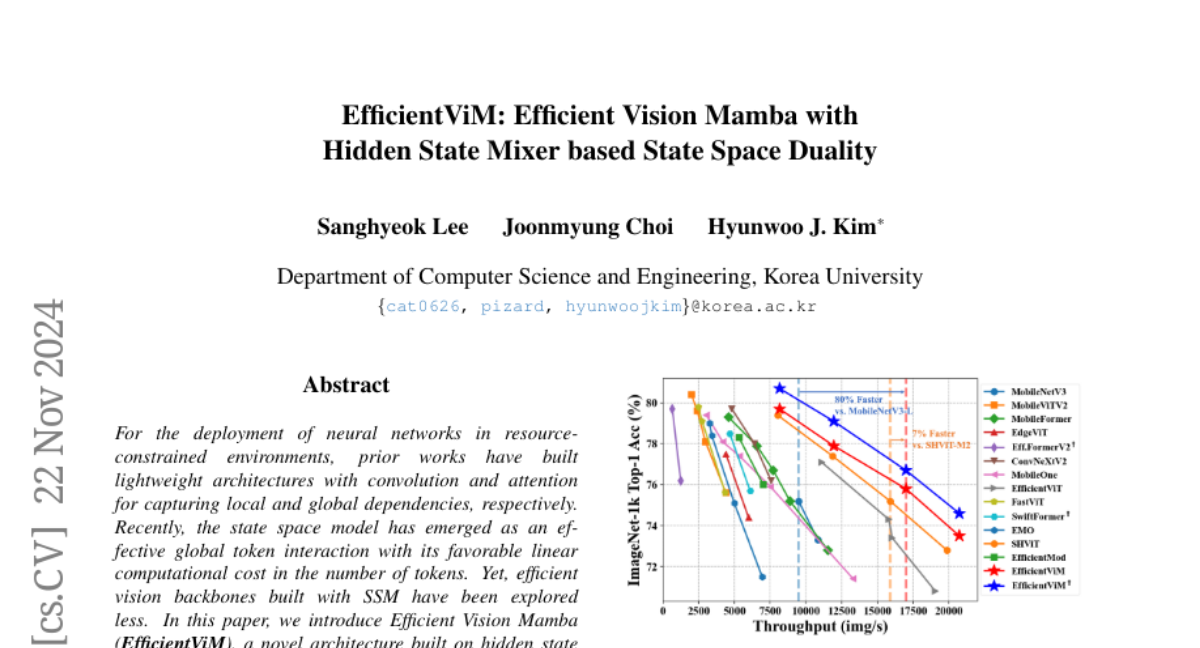
Новая Парадигма Оценки Глубины: PromptDepthAnything
Подсказки играют критическую роль в раскрытии потенциала языковых и визионных базовых моделей для конкретных задач. Впервые мы вводим подсказки в модели глубины, создавая новую парадигму для метрической оценки глубины, названную Prompt Depth Anything. В частности, мы используем недорогой LiDAR в качестве подсказки для управления моделью Depth Anything для точного метрического вывода глубины, достигая разрешения до 4K. Наш подход сосредоточен на компактном дизайне слияния подсказок, который интегрирует LiDAR на нескольких масштабах внутри декодера глубины. Чтобы справиться с проблемами обучения, вызванными ограниченными наборами данных, содержащими как глубину LiDAR, так и точную глубину GT, мы предлагаем масштабируемый конвейер данных, который включает в себя синтетическую симуляцию данных LiDAR и генерацию псевдо GT глубины из реальных данных. Наш подход устанавливает новые достижения на наборах данных ARKitScenes и ScanNet++ и приносит пользу downstream приложениям, включая 3D-реконструкцию и обобщенное робототехническое захватывание.