VideoGen-of-Thought: Коллаборативная структура для многослойной генерации видео
Недавние достижения в области генерации видео привели к впечатляющим результатам, особенно в создании коротких визуально привлекательных клипов. Однако, несмотря на успехи, существующие модели все еще сталкиваются с трудностями при создании многослойных видео, которые требуют логической согласованности и визуальной целостности. В данной статье мы обсудим новую архитектуру под названием VideoGen-of-Thought (VGoT), которая предназначена для решения этих проблем и создания многослойных видео, используя модульный и коллаборативный подход.
Проблема многослойной генерации видео
Существующие подходы
Существующие модели генерации видео часто фокусируются на создании коротких клипов и не способны поддерживать непрерывность и последовательность на протяжении нескольких сцен. Основное внимание уделяется увеличению продолжительности отдельных кадров, что не всегда приводит к логически связанным и визуально последовательным результатам. Модели, обученные на больших наборах данных, часто не справляются с задачами, связанными с многослойной генерацией видео.
Необходимость нового подхода
Существующие методы часто требуют значительных вычислительных ресурсов и времени на обучение, что делает их неэффективными для задач, требующих логической последовательности и визуальной согласованности. Поэтому существует необходимость в разработке нового подхода, который будет сочетать высокое качество визуализации с логической целостностью.
Архитектура VideoGen-of-Thought (VGoT)
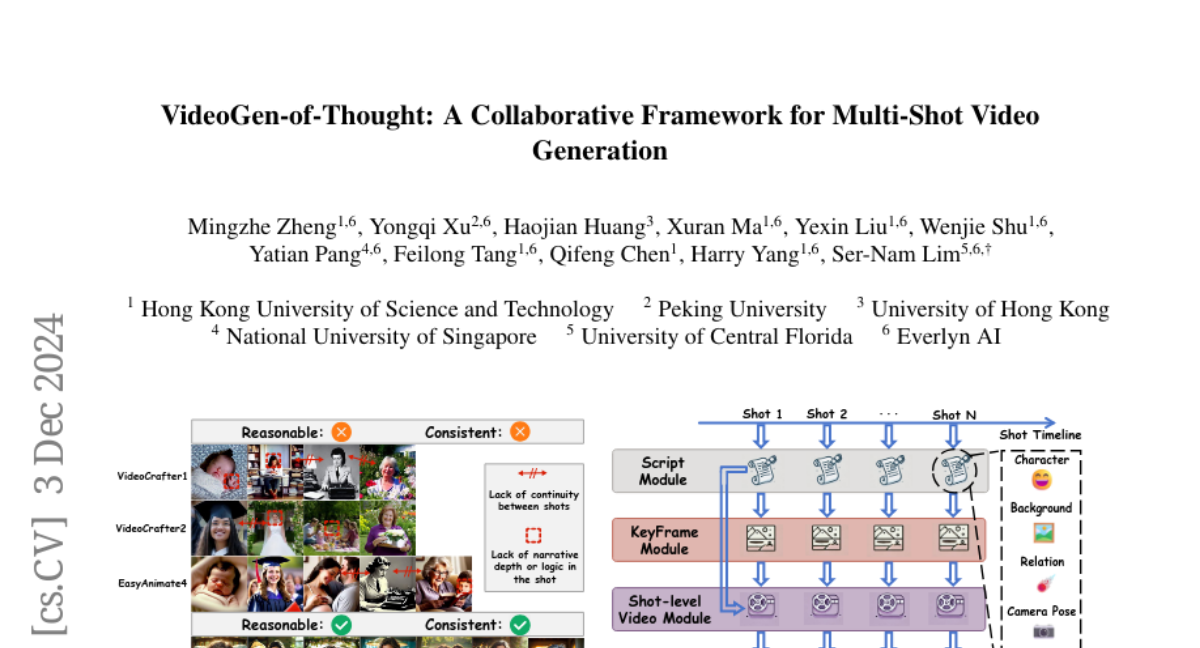
VGoT предлагает коллаборативную и безобучающуюся архитектуру, специально разработанную для многослойной генерации видео. Она включает в себя несколько ключевых компонентов, которые работают вместе, обеспечивая логическую последовательность и визуальную согласованность.
Модули VGoT
-
Модуль генерации сценария: Этот модуль преобразует краткое описание истории в детализированные подсказки для каждой сцены. Он обеспечивает логическую основу для всего видео, гарантируя, что каждая сцена соответствует общей нарративной структуре.
-
Модуль генерации ключевых кадров: Этот модуль создает визуально последовательные ключевые кадры на основе сценария. Он обеспечивает согласованность в изображении персонажей и окружения, что критически важно для поддержания визуальной целостности.
-
Модуль генерации видео на уровне сцен: Этот модуль преобразует информацию из сценариев и ключевых кадров в видеоряд. Он отвечает за создание видеопотока, который соответствует каждой сцене, обеспечивая плавность переходов между ними.
-
Механизм сглаживания: Этот механизм обеспечивает плавные переходы между сценами, гарантируя, что визуальная и нарративная непрерывность сохраняются на протяжении всего видео.
Процесс генерации видео
Процесс генерации видео в VGoT делится на несколько этапов:
-
Генерация сценария: Исходя из краткого описания, модуль сценария создает детализированные подсказки для каждой сцены. Эти подсказки охватывают пять ключевых областей: описание персонажей, фоновое окружение, отношения между персонажами, позы камеры и освещение.
-
Генерация ключевых кадров: На основе сценария создаются ключевые кадры, которые визуально представляют каждую сцену. Используются предварительно обученные модели для обеспечения согласованности визуального стиля и идентичности персонажей.
-
Генерация видео на уровне сцен: На этом этапе ключевые кадры и текстовые подсказки используются для создания видеорядов, которые представляют собой отдельные сцены. Модуль отвечает за создание видеопотока, который отображает динамику и действия персонажей.
-
Сглаживание переходов: После генерации всех сцен механизм сглаживания обрабатывает информацию, чтобы обеспечить плавные переходы между сценами, избегая резких изменений и визуальных несоответствий.
Преимущества VGoT
Логическая последовательность
VGoT обеспечивает логическую последовательность, используя модуль генерации сценария, который создает четкий нарративный поток. Это позволяет избежать резких переходов и обеспечивает непрерывность сюжета.
Визуальная согласованность
Использование идентифицирующих встраиваний (IP-embedding) для персонажей гарантирует, что их внешний вид остается последовательным на протяжении всего видео. Это особенно важно для поддержания зрительского восприятия и идентификации персонажей.
Плавные переходы
Механизм сглаживания, использующий информацию из соседних сцен, обеспечивает плавные переходы, что делает видео более естественным и приятным для восприятия.
Эксперименты и результаты
Эксперименты с VGoT показали, что он превосходит существующие методы генерации видео по качеству, согласованности и визуальной целостности. В ходе тестирования использовались различные истории, и результаты подтвердили, что VGoT способен создавать высококачественные, логически последовательные многослойные видео.
Оценка качества
Для количественной оценки качества генерации видео использовались различные метрики, такие как CLIP-оценка, PSNR и другие. Результаты показали, что VGoT значительно превосходит существующие модели по всем критериям, включая согласованность лиц и стилистическую согласованность.
Оценка пользователями
Пользовательские исследования также подтвердили высокую оценку качества видео, созданного VGoT. Участники отмечали, что видео, сгенерированные этой моделью, были более последовательными и логичными по сравнению с видео, созданными другими методами.
Заключение
VideoGen-of-Thought представляет собой значительный шаг вперед в области многослойной генерации видео. Его модульный и коллаборативный подход позволяет эффективно решать проблемы логической последовательности и визуальной согласованности, обеспечивая создание высококачественных видеопроектов. С учетом полученных результатов VGoT может стать основой для дальнейших исследований и разработок в области генерации видео, открывая новые возможности для создания креативного контента.