Важность Критических Токенов: Как Контрастная Оценка на Уровне Токенов Улучшает Способности Рассуждения LLM
В последние годы большие языковые модели (LLM) продемонстрировали впечатляющие результаты в задачах рассуждения. Эти модели используют автогрессивную генерацию токенов для построения логических цепочек, что позволяет им формировать последовательные и обоснованные ответы. Однако, несмотря на свои достижения, LLM сталкиваются с проблемами при выполнении сложных рассуждений, особенно когда речь идет о математических задачах. В данной статье мы рассмотрим исследование, посвященное выявлению "критических токенов" и их влиянию на конечные результаты рассуждений в LLM.
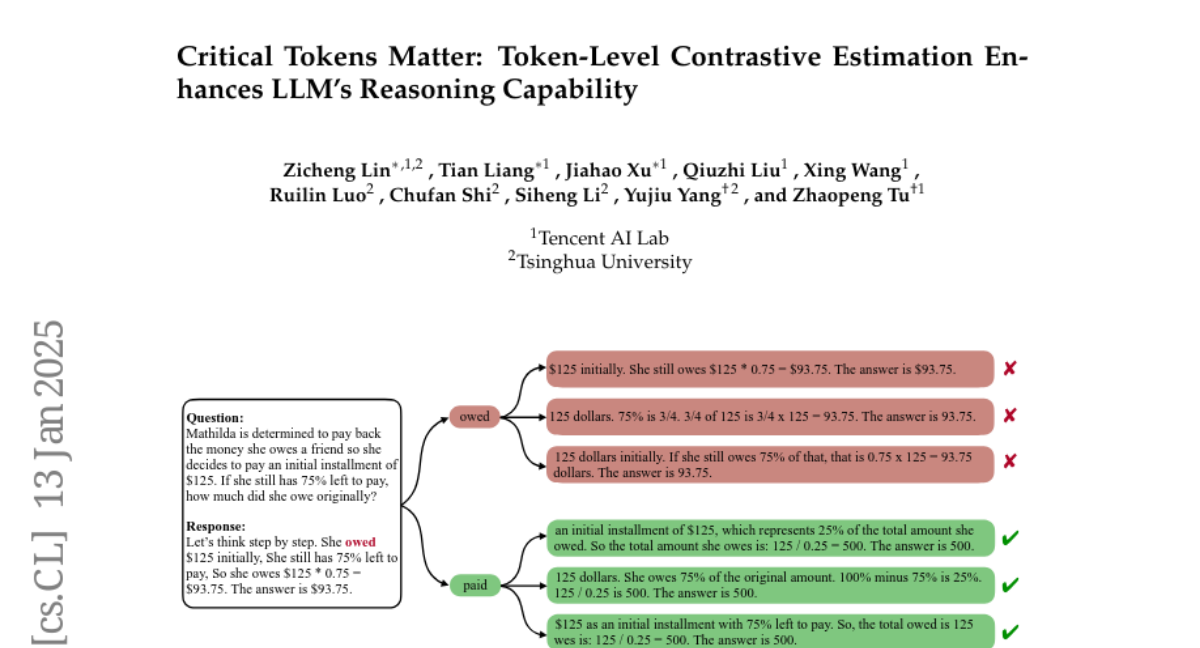
Критические Токены
Критические токены — это токены, которые играют решающую роль в формировании неправильных результатов в процессе рассуждения. Исследование показывает, что LLM часто выдают положительные результаты, когда им удается избегать декодирования этих критических токенов. Это открытие подчеркивает важность понимания того, какие токены вызывают ошибки в рассуждении, чтобы повысить точность моделей.
Пример Критического Токена
Рассмотрим пример: токен "owed" (долг) может привести к неправильным логическим выводам. Если модель заменяет этот токен на "paid" (оплачено), вероятность получения правильного ответа значительно возрастает. Это демонстрирует, что небольшие изменения в токенах могут привести к кардинально различным результатам.
Подход c-DPO
В ответ на выявление критических токенов, авторы предложили новый подход, называемый контрастной оценкой на уровне токенов (c-DPO). Этот метод автоматически распознает критические токены и назначает им вознаграждения на уровне токенов в процессе их выравнивания.
Контрастная Оценка
Контрастная оценка включает в себя сравнение вероятностей генерации токенов, созданных позитивной и негативной моделями. Позитивная модель обучается на правильных траекториях рассуждения, тогда как негативная модель обучается на неправильных. Это позволяет эффективно выявлять критические токены, которые способствуют неверным результатам.
Алгоритм c-DPO
Алгоритм c-DPO расширяет традиционные методы прямой оптимизации предпочтений (DPO) до уровня токенов. Он использует разницу в вероятностях между позитивной и негативной моделями как важный вес для обучения на уровне токенов. Это позволяет модели лучше справляться с задачами рассуждения, избегая критических токенов.
Экспериментальные Результаты
Для проверки эффективности предложенного подхода были проведены эксперименты с использованием двух популярных наборов данных: GSM8K и MATH500. Результаты показали, что c-DPO значительно превосходит предыдущие методы, такие как DPO и RPO, по точности и надежности.
Сравнение с Базовыми Методами
В исследованиях c-DPO достигла значительных улучшений по сравнению с базовыми методами. Например, на наборе данных GSM8K точность возросла до 77.2%, а на MATH500 — до 33.4%. Эти результаты подтверждают, что использование критических токенов и контрастной оценки на уровне токенов может существенно повысить способности LLM в задачах рассуждения.
Практическое Применение
Применение c-DPO может иметь широкий спектр практических применений, включая:
- Образование: Улучшение автоматизированных систем оценки и обучения, позволяя им более точно оценивать ответы студентов.
- Финансовые технологии: Повышение точности алгоритмов для анализа финансовых данных и принятия решений.
- Научные исследования: Упрощение анализа данных и выводов, основанных на сложных математических моделях.
Заключение
В заключение, исследование подчеркивает значимость критических токенов в процессе рассуждения LLM и предлагает эффективный метод их выявления с помощью c-DPO. Это открытие не только улучшает точность LLM в задачах рассуждения, но и предлагает новые пути для их применения в различных областях. Подход c-DPO может стать важным шагом в развитии более надежных и точных языковых моделей, способных справляться с сложными задачами рассуждения.