FluxSpace: Разделенное Семантическое Редактирование в Ректифицированных Потоковых Трансформерах
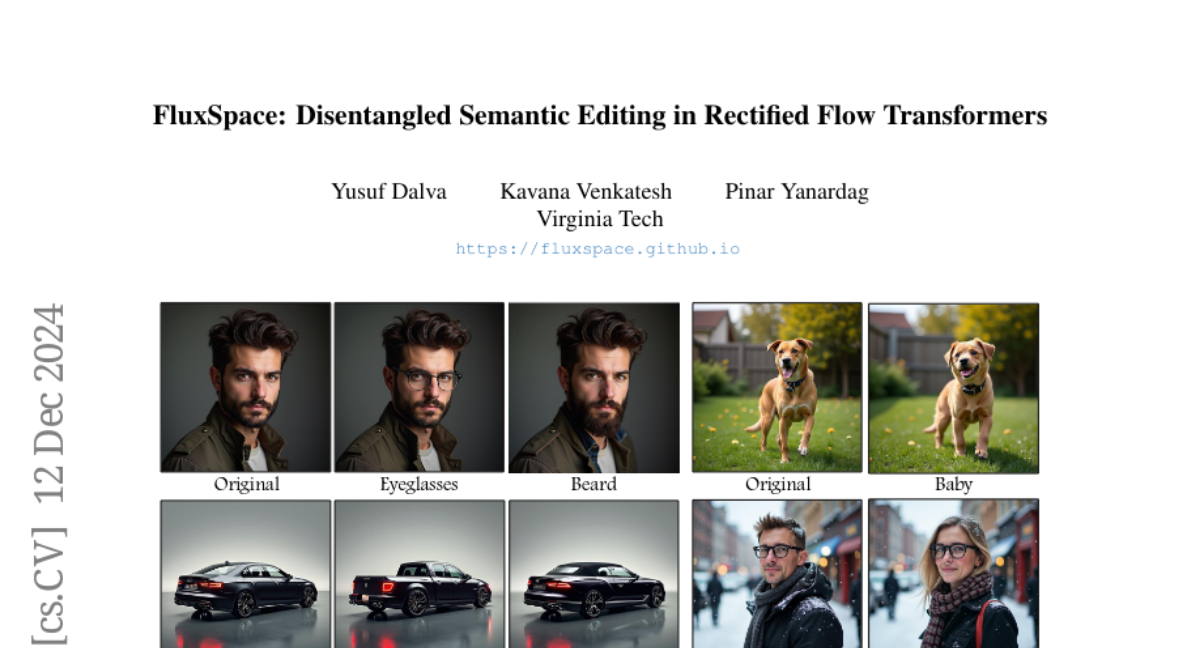
Модели исправленного потока стали доминирующим подходом в генерации изображений, демонстрируя впечатляющую способность к синтезу качественных изображений. Однако, несмотря на их эффективность в визуальной генерации, модели исправленного потока часто сталкиваются с трудностями в раздельном редактировании изображений. Это ограничение мешает возможности выполнять точные модификации, специфичные для атрибута, не затрагивая несвязанные аспекты изображения. В данной статье мы представляем FluxSpace, независимо от области метод редактирования изображений, использующий пространство представлений с возможностью контролировать семантику изображений, созданных исправленными потоковыми трансформерами, такими как Flux. Используя представления, полученные в трансформаторных блоках в рамках моделей исправленного потока, мы предлагаем набор семантически интерпретируемых представлений, которые позволяют выполнять широкий спектр задач редактирования изображений, от тонкого редактирования изображений до художественного создания. Эта работа предлагает масштабируемый и эффективный подход к редактированию изображений, а также его возможности раздельного редактирования.


