Случайная Авторегрессивная Визуализация
В последние годы автопрогрессивные (AR) модели значительно продвинулись вперёд в обработке естественного языка и компьютерном зрении. Они стали основой для больших языковых моделей (LLMs) таких как GPT, Llama и Gemini, а также показали значительный потенциал в задачах генерации изображений. Однако, несмотря на их успех в обработке текста, в визуальной генерации они часто уступают диффузионным моделям или неавтопрогрессивным трансформерам.
Основная причина этого заключается в различиях между текстом и визуальными сигналами: текст компактен и семантически значим, тогда как изображения более низкоуровневые и избыточные, что делает моделирование двунаправленного контекста более критичным. Ряд исследований показал, что причинно-следственное внимание к токенам изображений приводит к худшей производительности по сравнению с двунаправленным вниманием в задачах компьютерного зрения.
Для решения этой проблемы были предприняты попытки внедрить двунаправленное внимание в автопрогрессивные модели, но часто это требовало значительных изменений в традиционной автопрогрессивной парадигме. В этой статье мы представляем Randomized AutoRegressive (RAR) моделирование, которое улучшает качество генерации изображений автопрогрессивными моделями, сохраняя при этом их совместимость с фреймворками языкового моделирования.
Методология
Основы автопрогрессивного моделирования
Автопрогрессивное моделирование с целью предсказания следующего токена заключается в максимизации вероятности последовательности дискретных токенов $x = [x_1, x_2, ..., x_T]$:
$$ \max_{\theta} p_{\theta}(x) = \prod_{t=1}^{T} p_{\theta}(x_t | x_1, x_2, ..., x_{t-1}), $$
где $p_{\theta}$ - это предсказатель распределения токенов, параметризованный $\theta$. Каждый токен $x_t$ на позиции $t$ предсказывается на основе всех предшествующих токенов, что ограничивает контекстное моделирование только однонаправленным образом.
RAR: Случайное Автопрогрессивное Моделирование
Визуальные сигналы имеют двунаправленные корреляции, что делает эффективное глобальное контекстное моделирование важным. Однако традиционные автопрогрессивные модели используют причинно-следственное маскирование внимания, что противоречит природе визуальных данных. Мы предлагаем модифицировать оптимизационную цель следующим образом:
$$ \max_{\theta} p_{\theta}(x) = \prod_{t=1}^{T} p_{\theta}(x_t | x_1, ..., x_{t-1}, x_{t+1}, ..., x_T), $$
где модель обучается предсказывать каждый токен на основе всех остальных токенов в последовательности. Это позволяет модели учитывать двунаправленный контекст в процессе обучения.
Перестановка токенов
Для реализации этого подхода, мы случайным образом переставляем входную последовательность токенов с вероятностью $r$, где $r$ начинается с 1 и линейно уменьшается до 0 в процессе обучения. Это позволяет модели максимизировать ожидаемую вероятность по всем возможным порядкам перестановок:
$$ \max_{\theta} p_{\theta}(x) = \mathbb{E}{\tau \sim S_T} \left[ \prod{t=1}^{T} p_{\theta}(x_{\tau_t} | x_{\tau_{<t}}) \right], $$
где $S_T$ - множество всех возможных перестановок индексов последовательности $[1, 2, ..., T]$, и $\tau$ - случайно выбранная перестановка из $S_T$.
Целевое позиционное вложение
Одной из проблем перестановочного обучения является возможность получения одинаковых предсказаний для разных перестановок. Чтобы решить эту проблему, мы вводим целевое позиционное вложение, которое информирует модель о том, какой токен следует предсказать следующим:
$$ \hat{x}{\tau} = x{\tau} + p_{\tau}, $$
где $x_{\tau}$ - переставленные токены, а $p_{\tau}$ - соответствующие им позиционные вложения.
Аннеалинг случайности
Для балансировки между случайными перестановками и фиксированным порядком сканирования (например, растровым), мы вводим параметр $r$, который контролирует вероятность использования случайной перестановки:
$$ r = \begin{cases} 1.0, & \text{if epoch < start} \ 0.0, & \text{if epoch > end} \ 1.0 - \frac{\text{epoch} - \text{start}}{\text{end} - \text{start}}, & \text{otherwise} \end{cases} $$
где start и end - эпохи, на которых начинается и заканчивается аннеалинг.
Экспериментальные результаты
Реализация
Мы реализовали RAR на основе автопрогрессивного фреймворка языкового моделирования с минимальными изменениями. Использовали VQ-токенизатор для преобразования изображений в дискретные последовательности токенов и автопрогрессивный трансформер с различными конфигурациями модели.
Аблиционные исследования
Стратегия аннеалинга случайности
Мы исследовали различные стратегии аннеалинга случайности, изменяя параметры start и end. Наилучшие результаты были получены при start = 200 и end = 300, что улучшило FID с 3.08 до 2.18.
Различные порядки сканирования
Мы также изучили влияние различных порядков сканирования на конечную производительность RAR. Были рассмотрены шесть различных порядков: row-major, spiral-in, spiral-out, z-curve, subsample, и alternate. Наилучшие результаты показал порядок row-major, который и был выбран для всех финальных моделей RAR.
Основные результаты
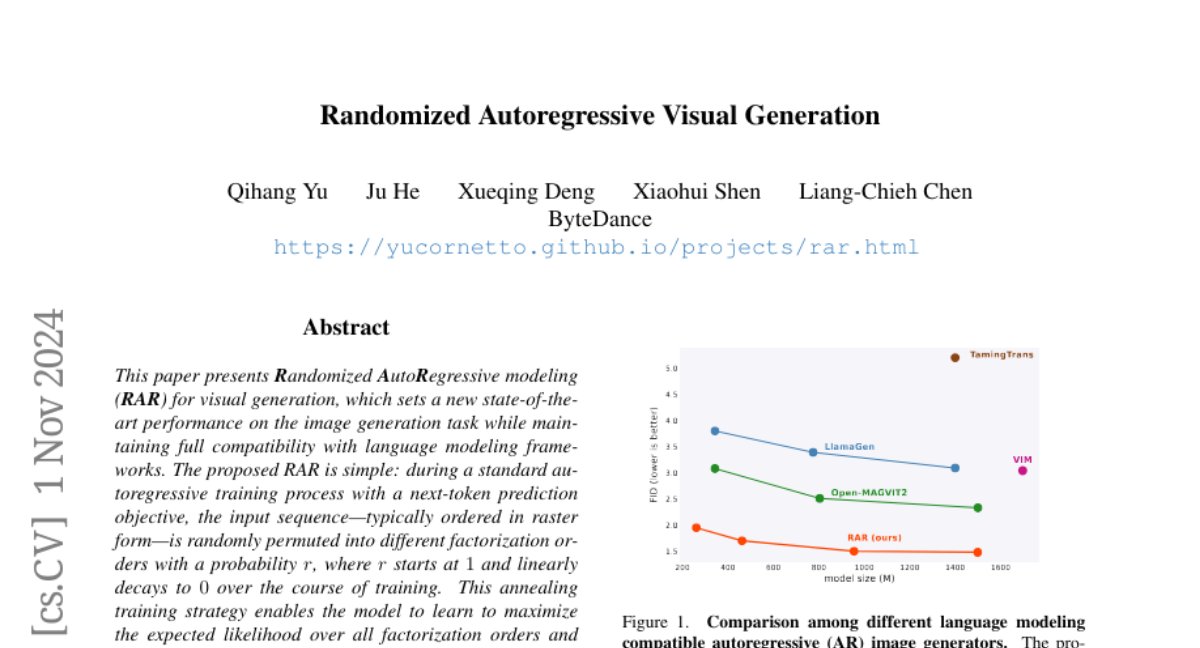
RAR значительно улучшил качество генерации изображений по сравнению с предыдущими автопрогрессивными генераторами изображений. Наиболее компактная модель RAR-B с 261M параметрами достигла FID 1.95, превзойдя LlamaGen-3B-384 и Open-MAGVIT2-XL, используя на 91% и 81% меньше параметров соответственно. Более крупные варианты RAR показали ещё более впечатляющие результаты, с RAR-XXL, установив новый рекорд FID на 1.48 на бенчмарке ImageNet-256.
Скорость генерации
Одним из преимуществ автопрогрессивных методов является возможность использования оптимизационных техник из LLM, таких как KV-кэширование. RAR показал превосходство в скорости генерации по сравнению с другими методами, достигая 8.3 изображений в секунду для RAR-XL, что в 11.9 раз быстрее, чем MaskBit и в 27.7 раз быстрее, чем MAR-H при аналогичном FID.
Масштабируемость
RAR демонстрирует хорошую масштабируемость, где увеличение размера модели приводит к снижению обучающих потерь и улучшению FID-скоров, независимо от использования классификаторно-свободного руководства.
Заключение
В этой статье мы представили RAR, простую, но эффективную стратегию для улучшения качества визуальной генерации автопрогрессивными моделями, совместимыми с фреймворками языкового моделирования. Используя случайную перестановку токенов, RAR позволяет улучшить двунаправленное контекстное обучение, сохраняя при этом автопрогрессивную структуру. В результате, RAR превзошел предыдущие автопрогрессивные модели генерации изображений, а также ведущие неавтопрогрессивные трансформеры и диффузионные модели. Мы надеемся, что это исследование внесет вклад в развитие автопрогрессивных трансформеров к единой платформе для понимания и генерации визуальных данных.