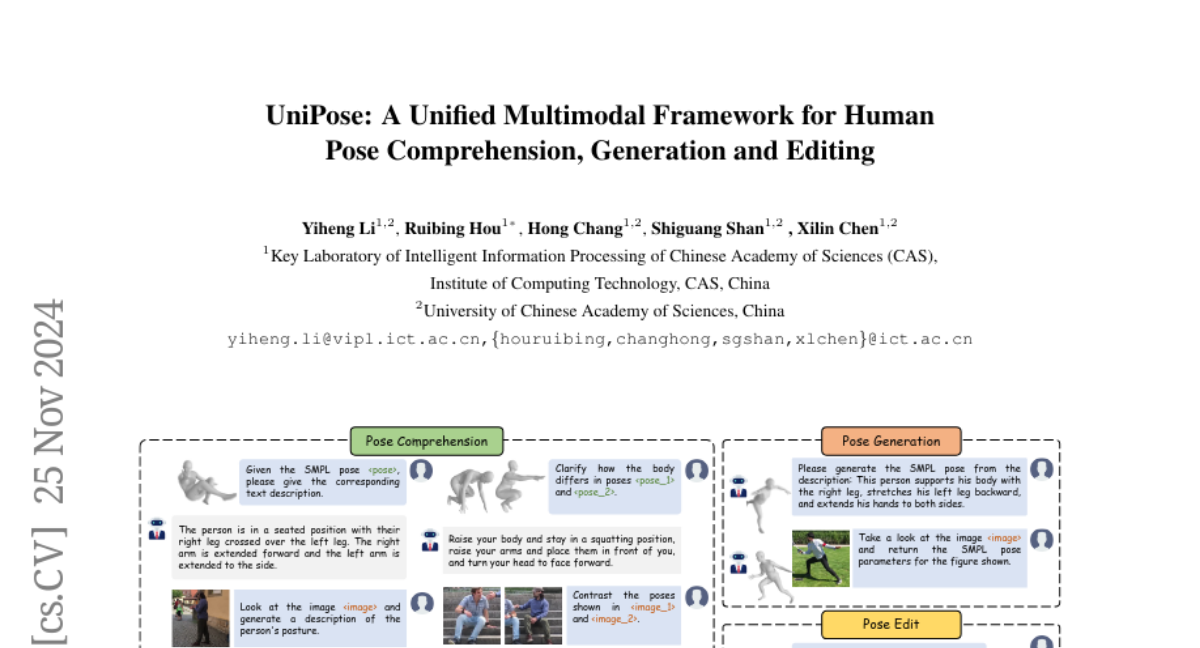
UniPose: Единная мультимодальная структура для понимания, генерации и редактирования человеческой позы
В современном цифровом мире понимание человеческой позы стало важным аспектом различных приложений, таких как виртуальная реальность (VR) и здравоохранение. Хотя недавние исследования достигли значительного прогресса в этой области, они часто фокусируются лишь на одной модальности контроля, что ограничивает их применение в реальных сценариях. В ответ на эти ограничения была разработана структура UniPose, использующая большие языковые модели (LLMs) для понимания, генерации и редактирования человеческих поз, охватывающая различные модальности, включая изображения, текст и 3D-позы SMPL.
Проблемы существующих подходов
Существующие методы в области понимания и генерации поз обычно исследуются изолированно. Это приводит к недостатку интеграции между различными задачами, связанными с позами. Например, многие из них не могут эффективно обрабатывать переходы между 3D-позами и текстовыми описаниями. Кроме того, существующие мультимодальные языковые модели (MLLMs) часто не обеспечивают детального анализа человеческих поз, особенно в отношении семантики частей тела и сложных взаимосвязей между парами поз.
Основные концепции UniPose
UniPose представляет собой единую мультимодальную структуру, которая включает три основных компонента:
-
Токенизатор поз: Этот компонент преобразует 3D-позы в дискретные токены, что позволяет интегрировать их в LLM. Это достигается путем сжатия 3D-позы в последовательность семантических токенов, что упрощает взаимодействие между различными модальностями.
-
Визуальный процессор: Он извлекает детальные характеристики, относящиеся к позам, из визуальных входных данных. UniPose использует смесь визуальных энкодеров, включая предобученный энкодер для оценки поз, что улучшает восприятие поз и позволяет более эффективно интегрировать визуальные данные в мультимодальную структуру.
-
Языковая модель, учитывающая позы: Эта модель поддерживает единое моделирование различных задач, связанных с позами, что позволяет выполнять задачи понимания, генерации и редактирования поз в рамках одной структуры.
Обучение UniPose
Процесс обучения UniPose состоит из четырех этапов:
-
Обучение токенизатора поз: На этом этапе токенизатор обучается на основе 3D-поз, чтобы преобразовать их в последовательности дискретных токенов.
-
Предварительное обучение на корпусе текста и поз: Этот этап включает в себя обучение LLM на корпусе, который связывает текстовые и позовые данные, что позволяет модели лучше понимать и генерировать описания поз.
-
Предварительное обучение визуального проектора: На этом этапе модель обучается на задачах, связанных с изображениями и текстами, чтобы улучшить соответствие визуальных данных языковым моделям.
-
Настройка на инструкции: На последнем этапе производится совместное обучение визуального проектора и LLM с использованием набора данных, содержащего различные инструкции для выполнения задач.
Эксперименты и результаты
Эксперименты, проведенные с UniPose, продемонстрировали его конкурентоспособность и даже превосходство по сравнению с существующими методами в различных задачах, связанных с позами. Например, в задачах понимания поз UniPose показал высокие результаты в сопоставлении текстов и поз, а также в генерации описаний на основе визуальных данных.
Сравнение с существующими методами
UniPose был протестирован на нескольких задачах, включая понимание поз, генерацию поз и редактирование. Результаты показали, что UniPose значительно превосходит существующие модели, такие как ChatPose и PoseFix, особенно в задачах, требующих детального анализа поз и их взаимосвязей.
Переход к нулевым задачам
UniPose также продемонстрировал способности к обобщению без дополнительного обучения, что позволяет ему адаптироваться к новым задачам. Это особенно полезно в сценариях, где точность оценки поз может быть затруднена из-за неоднозначности или перекрытия объектов на изображениях.
Заключение
UniPose представляет собой первый шаг к созданию универсальной структуры для понимания, генерации и редактирования человеческой позы. Используя токенизатор поз и смесь визуальных энкодеров, UniPose обеспечивает более глубокое понимание поз и их взаимосвязей, что делает его мощным инструментом для различных приложений в области компьютерного зрения и обработки естественного языка.
Таким образом, UniPose открывает новые горизонты для исследований в области понимания человеческой позы и может быть использован в различных областях, таких как анимация, виртуальная реальность и медицинская диагностика, где понимание человеческой позы играет ключевую роль.