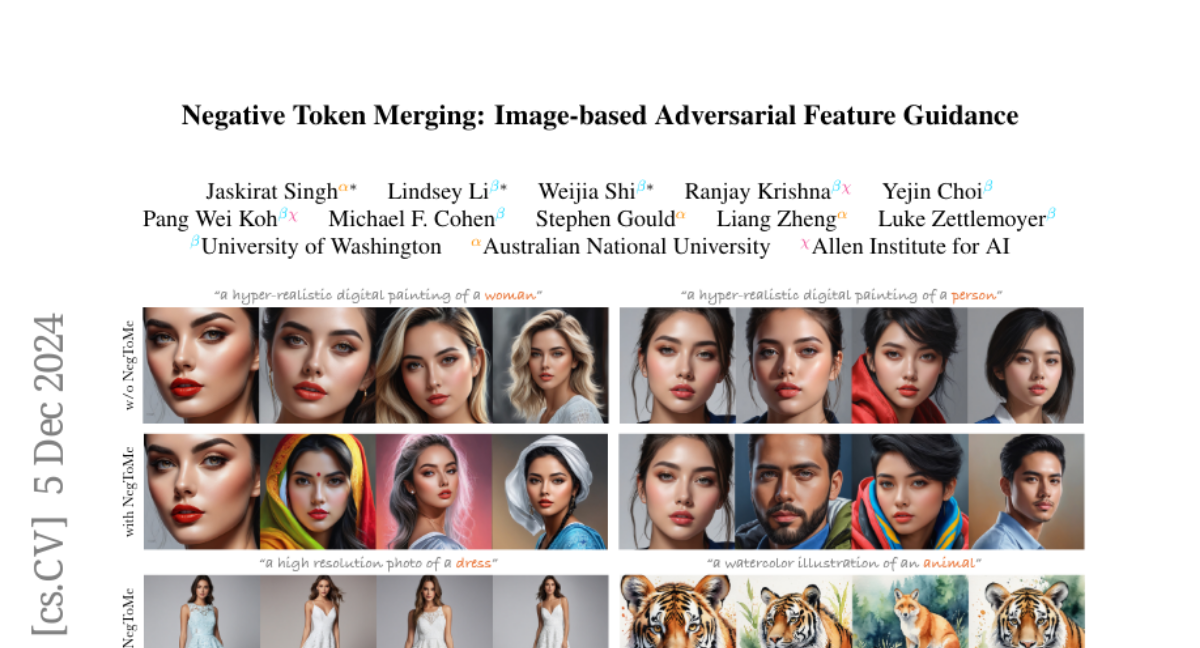
KV-Shifting Attention: Новая Эра в Языковом Моделировании
Современные крупные языковые модели в основном основаны на структуре трансформеров только декодирования, которые обладают отличными способностями к обучению в контексте (ICL). Общее мнение заключается в том, что важной основой её способности ICL является механизм индукционных голов, который требует как минимум два слоя внимания. Чтобы более эффективно реализовать способность индукции модели, мы пересматриваем механизм индукционных голов и предлагаем внимание с перемещением KV. Мы теоретически доказываем, что внимание с перемещением KV снижает требования модели к глубине и ширине механизма индукционных голов. Наши экспериментальные результаты демонстрируют, что внимание с перемещением KV благоприятно сказывается на обучении индукционных голов и языковом моделировании, что приводит к лучшей производительности или более быстрой сходимости от игрушечных моделей к моделям предварительного обучения с более чем 10 миллиардами параметров.