Negative Token Merging: Новые горизонты в управлении генерацией изображений
Современные модели диффузии, такие как текстово-изображенческие (T2I) модели, достигли значительных успехов в генерации качественных изображений. Тем не менее, управление процессом генерации, особенно в контексте избегания нежелательных концепций, остается сложной задачей. Традиционно для этого используются негативные подсказки, которые помогают направить генерацию в нужном направлении. Однако, как показывает практика, использование только текстовых подсказок не всегда эффективно для сложных визуальных концепций или для избежания конкретных визуальных элементов, таких как защищенные авторским правом персонажи.
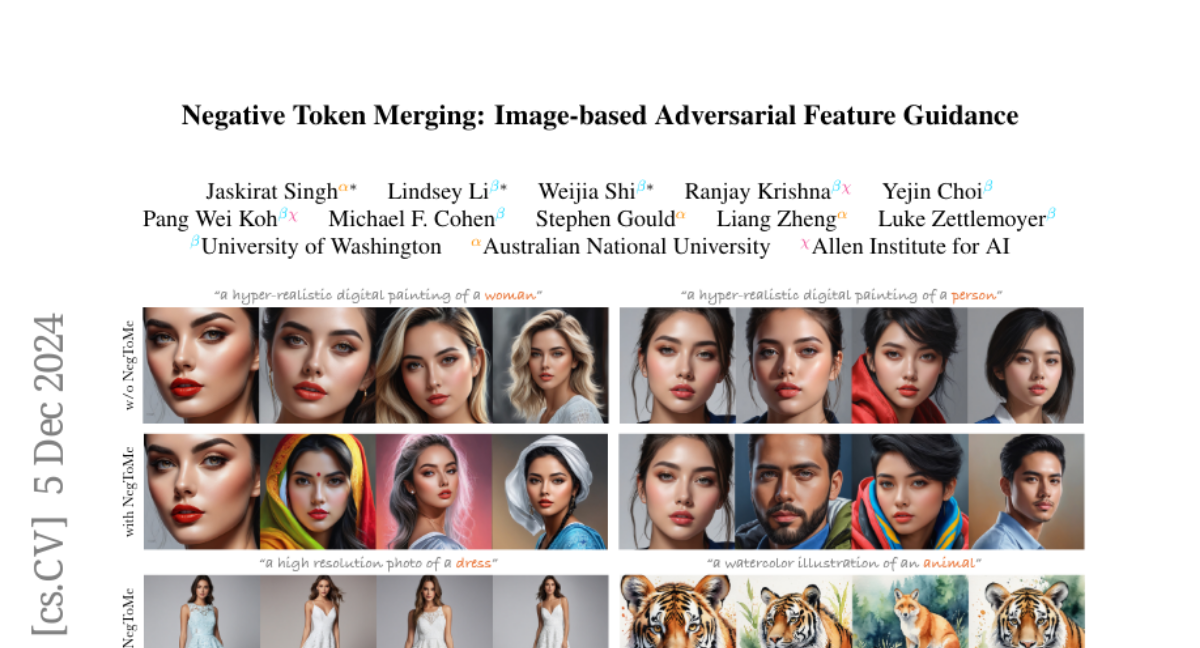
В данной статье мы представляем новый подход, названный Negative Token Merging (NegToMe), который использует визуальные характеристики из ссылочных изображений для управления процессом генерации. Этот метод не требует предварительного обучения и может быть легко интегрирован в существующие архитектуры диффузии.
Основные концепции
Проблемы существующих методов
Существующие методы управления генерацией изображений с помощью негативных подсказок сталкиваются с несколькими ограничениями:
- Сложность описания: Текстовые подсказки могут быть недостаточно точными для передачи сложных визуальных концепций. Например, попытка описать позу, действие и фон может быть затруднительной.
- Недостаточная эффективность: Использование негативных подсказок не всегда позволяет избежать нежелательных визуальных элементов, таких как защищенные авторским правом персонажи.
- Ограничения в архитектурах: Некоторые современные модели, такие как Flux, не поддерживают использование отдельных негативных подсказок.
Подход NegToMe
NegToMe предлагает альтернативный подход, который использует визуальные признаки из ссылочных изображений для управления процессом генерации. Этот метод включает в себя три ключевых этапа:
-
Семантическое сопоставление токенов: На первом этапе происходит сопоставление токенов, сгенерированных моделью, с токенами из ссылочного изображения. Это позволяет определить, какие визуальные элементы наиболее близки друг к другу.
-
Слияние токенов: На втором этапе происходит слияние токенов, основываясь на их семантическом сходстве. Это позволяет "раздвинуть" визуальные элементы, которые слишком похожи друг на друга.
-
Линейная экстраполяция: На третьем этапе применяется линейная экстраполяция для дальнейшего "раздвижения" токенов, что помогает избежать визуального сходства с нежелательными элементами.
Преимущества метода
NegToMe имеет несколько ключевых преимуществ:
- Увеличение разнообразия: Метод позволяет значительно увеличить разнообразие выходных изображений, избегая проблемы "модового коллапса", когда генерация приводит к слишком похожим результатам.
- Снижение визуального сходства: NegToMe позволяет уменьшить визуальное сходство с защищенными авторским правом персонажами на 34.57%.
- Простота реализации: Метод можно реализовать всего за несколько строк кода и он совместим с различными архитектурами диффузии.
Применение NegToMe
Увеличение разнообразия выходных изображений
Одним из основных применений NegToMe является улучшение разнообразия выходных изображений. Исследования показывают, что современные модели часто страдают от ограниченного разнообразия, особенно в контексте расовой и гендерной идентичности. Используя NegToMe, можно направить визуальные признаки каждого изображения в разные стороны, что способствует созданию более разнообразных выходных данных.
Снижение визуального сходства с защищенными персонажами
Еще одним важным применением NegToMe является снижение визуального сходства с защищенными авторским правом персонажами. Использование визуальных характеристик из ссылочных изображений позволяет более эффективно управлять генерацией, избегая нежелательных элементов, которые могут привести к юридическим последствиям.
Улучшение эстетики изображений
NegToMe также может быть использован для улучшения эстетики выходных изображений. Например, использование размытых или низкокачественных ссылочных изображений может помочь в создании более качественных и эстетически привлекательных выходных данных.
Эксперименты и результаты
Увеличение разнообразия
В рамках экспериментов по увеличению разнообразия выходных изображений, было проведено сравнение результатов генерации с и без использования NegToMe. Результаты показали, что использование метода значительно улучшает разнообразие выходных данных, сохраняя при этом высокое качество изображений.
Снижение визуального сходства
В экспериментах по снижению визуального сходства с защищенными персонажами, NegToMe продемонстрировал значительное снижение визуального сходства, что подтверждает его эффективность в этой области.
Оценка качества изображений
Качество изображений также было оценено с помощью различных метрик, таких как FID (Frechet Inception Distance) и CLIP Score. Результаты показали, что использование NegToMe не только увеличивает разнообразие, но и улучшает общее качество изображений.
Заключение
В данной статье представлен новый подход к управлению генерацией изображений, основанный на использовании визуальных характеристик из ссылочных изображений. NegToMe является простым и эффективным методом, который позволяет значительно увеличить разнообразие выходных данных и снизить визуальное сходство с защищенными авторским правом персонажами. Этот подход открывает новые горизонты для использования моделей диффузии в творческих приложениях.
Мы надеемся, что результаты нашего исследования помогут пользователям более эффективно использовать современные модели генерации изображений для достижения разнообразных и качественных результатов.