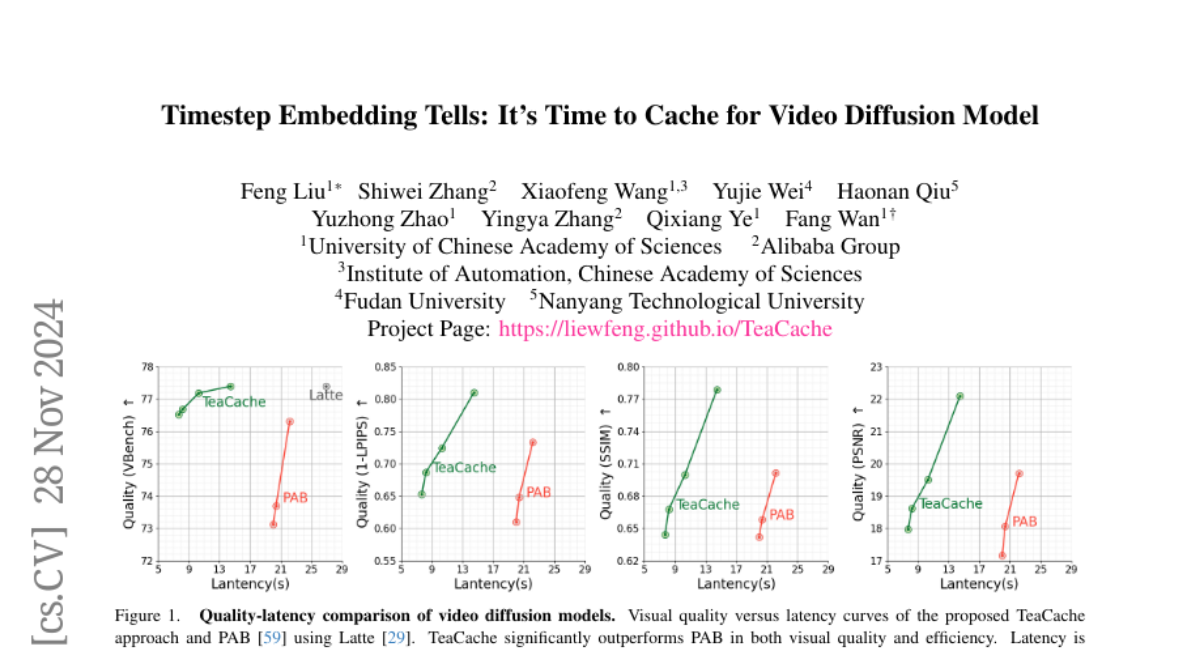
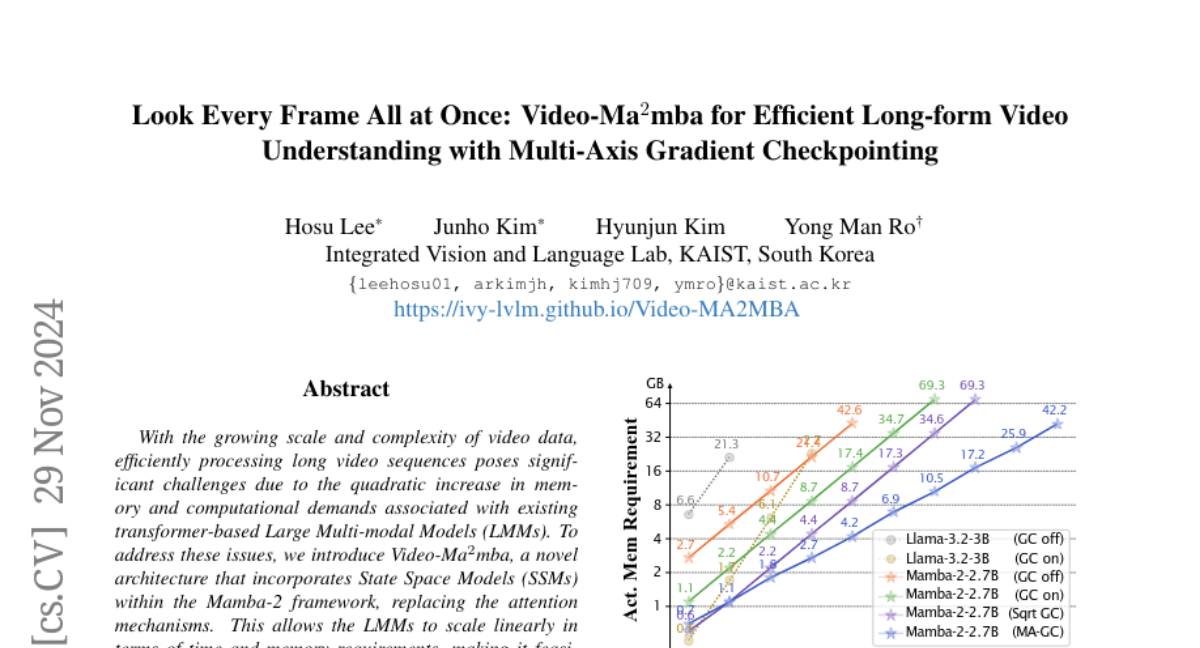
Несмотря на недавние достижения моделей взаимодействия «лицом к лицу» (VLA) в различных задачах робототехники, они страдают от критических проблем, таких как плохая обобщаемость к невиданным задачам из-за их зависимости от клонирования поведения исключительно на основе успешных тренингов. Более того, они обычно настраиваются для воспроизведения демонстраций, собранных экспертами в различных условиях, что вводит искажения распределения и ограничивает их адаптируемость к различным целям манипуляции, таким как эффективность, безопасность и завершение задачи. Чтобы преодолеть эту пропасть, мы представляем GRAPE: Обобщение политики робота через согласование предпочтений. Конкретно, GRAPE выравнивает VLA на уровне траектории и неявно моделирует вознаграждение как от успешных, так и неудачных испытаний для повышения обобщаемости к разнообразным задачам. Кроме того, GRAPE разбивает сложные задачи манипуляции на независимые этапы и автоматически направляет моделирование предпочтений через индивидуальные пространственно-временные ограничения с контрольными точками, предложенными большой моделью «лицом к лицу». Примечательно, что эти ограничения гибкие и могут быть настроены для согласования модели с различными целями, такими как безопасность, эффективность или успех задачи. Мы оцениваем GRAPE в различных задачах как в реальном, так и в смоделированном окружении. Экспериментальные результаты показывают, что GRAPE повышает производительность современных VLA моделей, увеличивая коэффициенты успеха для задач манипуляции на их области применения и невиданных задач на 51,79% и 60,36% соответственно. Кроме того, GRAPE может быть согласована с различными целями, такими как безопасность и эффективность, снижая частоту столкновений на 44,31% и длину шага раската на 11,15% соответственно. Весь код, модели и данные доступны по адресу https://grape-vla.github.io/.