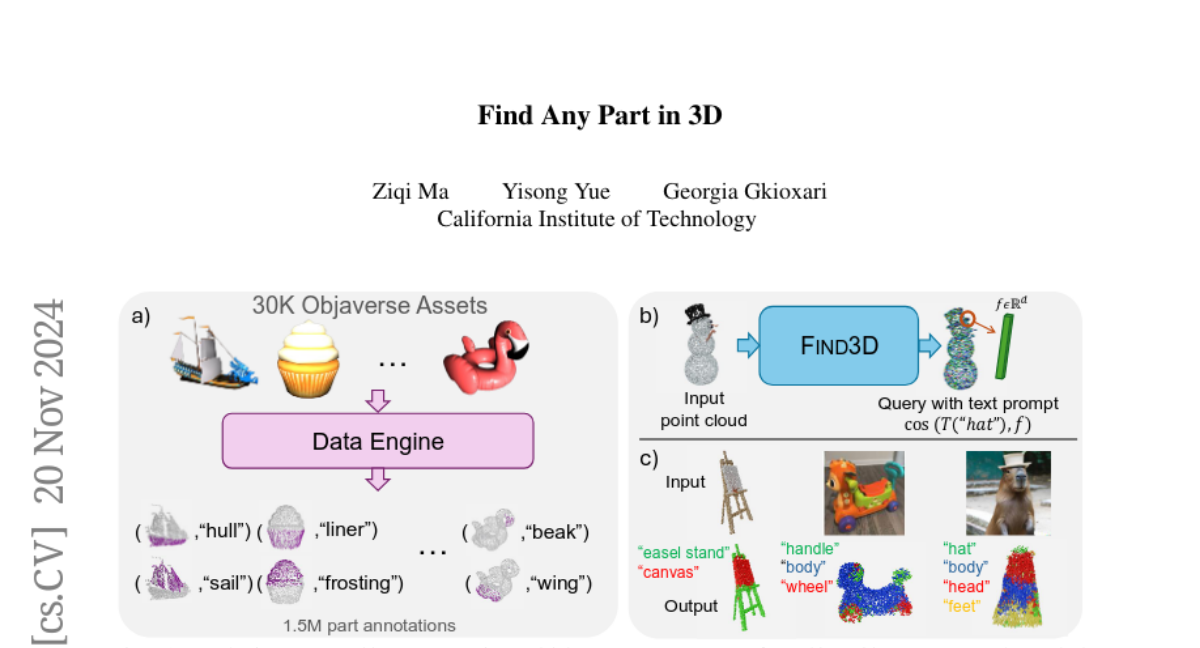
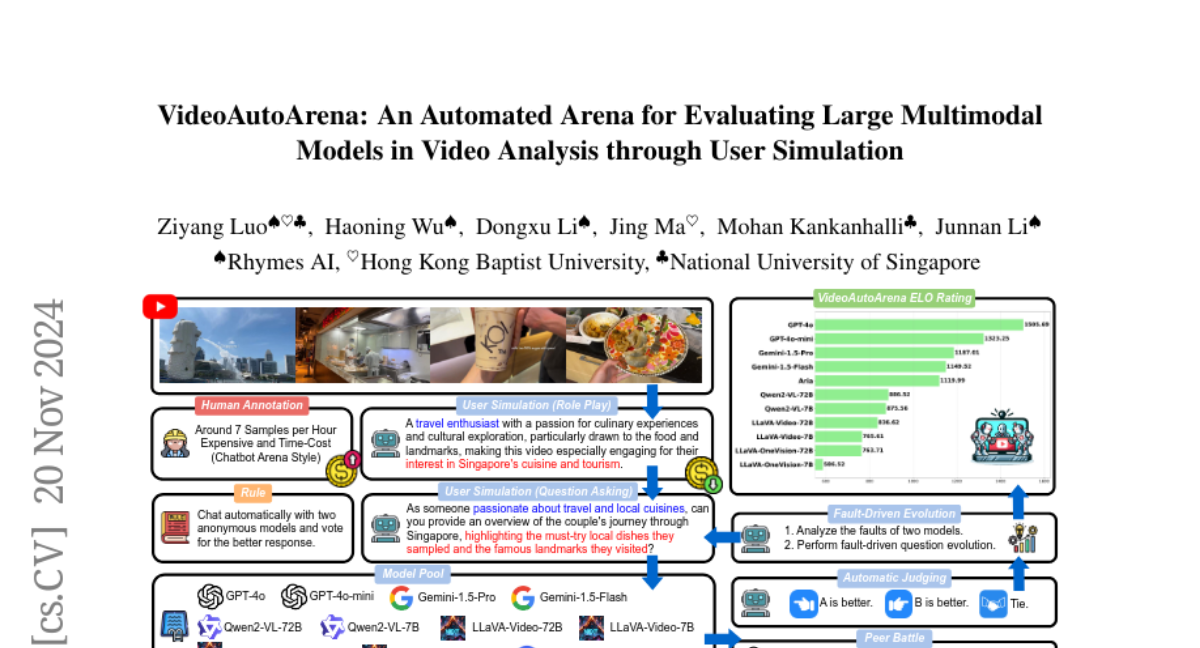
LiFT: Использование человеческой обратной связи для выравнивания моделей текст-видео
Недавние достижения в генеративных моделях преобразования текста в видео (T2V) продемонстрировали впечатляющие возможности. Однако эти модели все еще недостаточны для согласования синтезированных видео с человеческими предпочтениями (например, точного отражения текстовых описаний), что особенно трудно решить, поскольку человеческие предпочтения по своей природе субъективны и сложно формализуемы как объективные функции. Поэтому в статье предлагается метод тонкой настройки LiFT, использующий человеческую обратную связь для согласования моделей T2V. Конкретно, мы сначала создаем набор данных аннотации человеческой оценки, LiFT-HRA, состоящий из примерно 10 000 аннотаций, каждая из которых включает оценку и соответствующее обоснование. На основе этого мы обучаем модель вознаграждения LiFT-Critic для эффективного изучения функции вознаграждения, которая служит прокси для человеческой оценки, измеряя согласование между данными видео и ожиданиями человека. Наконец, мы используем изученную функцию вознаграждения для согласования модели T2V, максимизируя взвешенную по вознаграждению вероятность. В качестве примера мы применяем наш конвейер к CogVideoX-2B, показывая, что тонко настроенная модель превосходит CogVideoX-5B по всем 16 метрикам, подчеркивая потенциал человеческой обратной связи в улучшении согласования и качества синтезированных видео.