VideoAutoArena: Автоматизированная арена для оценки крупномасштабных мультимодальных моделей в анализе видео через симуляцию пользователя
В последние годы крупномасштабные мультимодальные модели (LMMs) с продвинутыми возможностями анализа видео, такие как GPT-4o, Gemini-1.5-Pro, Aria, Qwen2-VL и LLaVa-Video, привлекли значительное внимание в сообществе искусственного интеллекта. Эти модели расширяют границы традиционных моделей, работающих с изображениями, предоставляя возможность обрабатывать динамические данные видео, что делает их идеальными для анализа сложных видео последовательностей. Однако большинство текущих методов оценки этих моделей ограничены традиционными подходами, такими как ответы на многовариантные вопросы в бенчмарках, которые не в полной мере отражают сложные требования реальных пользователей.
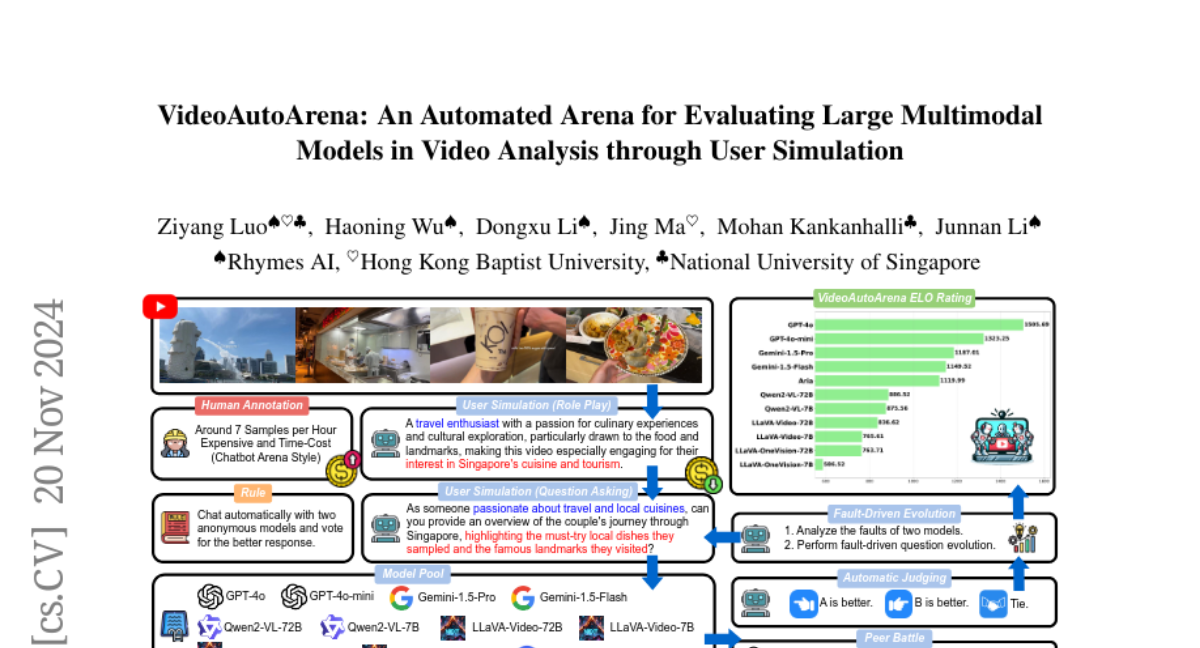
В этом контексте мы представляем VideoAutoArena — автоматизированную арену для оценки LMMs в анализе видео, вдохновленную платформой LMSYS Chatbot Arena. VideoAutoArena использует симуляцию пользователя для генерации открытых, адаптивных вопросов, которые тщательно оценивают производительность моделей в понимании видео. Этот бенчмарк предлагает масштабируемую и эффективную альтернативу дорогостоящим и трудоемким человеческим аннотациям, обеспечивая при этом точную и справедливую оценку моделей.
Обзор VideoAutoArena
Компоненты VideoAutoArena
-
Симуляция пользователя: Используя LMMs в качестве агентов, VideoAutoArena генерирует вопросы, которые имитируют запросы реальных пользователей, интересующихся видео контентом. Это включает в себя определение персон, которые могут быть заинтересованы в видео, и создание вопросов, соответствующих их интересам.
-
Парные битвы: Два случайно выбранных LMMs конкурируют, отвечая на один и тот же вопрос, сформулированный на основе видео. Это позволяет сравнить качество ответов и определить, какой из моделей предоставляет лучший ответ.
-
Автоматическое судейство: Вместо человеческих аннотаторов, используется система автоматического судейства, которая оценивает ответы моделей по нескольким критериям, включая точность, релевантность, полезность и следование инструкциям.
-
Эволюция вопросов на основе ошибок: Вопросы усложняются на основе анализа ответов моделей, чтобы выявить слабые места и улучшить их способности к анализу видео.
Процесс оценки
- Сбор данных: VideoAutoArena использует 2,881 видео из LongVideoBench с различной продолжительностью и тематикой.
- Генерация вопросов: Для каждого видео агенты создают вопросы, отражающие интересы различных персон.
- Конкуренция моделей: Модели отвечают на вопросы, и их ответы сравниваются.
- Судейство: Используется LMM-as-a-Judge для автоматического определения победителя в каждом сравнении.
- Рейтинг: Модели ранжируются с использованием модифицированной системы рейтинга ELO, которая учитывает результаты всех битв.
Эксперименты и результаты
Установка эксперимента
В экспериментах участвовали 11 ведущих LMMs, включая как проприетарные, так и открытые модели. Каждое видео было равномерно сэмплировано для предоставления 64 кадров в качестве входных данных для генерации ответов, а для судейства использовались 128 кадров.
Результаты
- Рейтинг ELO: В общем рейтинге ELO, GPT-4o занял лидирующую позицию с рейтингом 1505.69, значительно опережая открытые модели, такие как Aria, с разрывом в 385.7 баллов.
- Производительность на различных длинах видео: Видно, что разрыв между моделями увеличивается с увеличением длины видео, особенно для сложных вопросов.
- Сравнение с традиционными бенчмарками: VideoAutoArena показала более значительные различия между моделями по сравнению с традиционными многовариантными вопросами, подчеркивая ее способность выявлять более тонкие различия в производительности.
Примеры битв
В одном из примеров битвы между Aria и LLaVa-Video-72B, Aria предоставила более подробный и полезный ответ на вопрос о символике флага Гватемалы, что позволило ей победить в этом сравнении.
Заключение
VideoAutoArena представляет собой инновационный подход к оценке LMMs в анализе видео, предлагая более реалистичную и масштабируемую альтернативу традиционным методам. Используя симуляцию пользователя, автоматическое судейство и эволюцию вопросов на основе ошибок, этот бенчмарк не только обеспечивает глубокое понимание способностей моделей, но и предлагает направления для их дальнейшего улучшения. Вместе с VideoAutoBench, который упрощает процесс оценки, VideoAutoArena открывает новые возможности для исследований и разработки в области видео анализа с использованием LMMs.