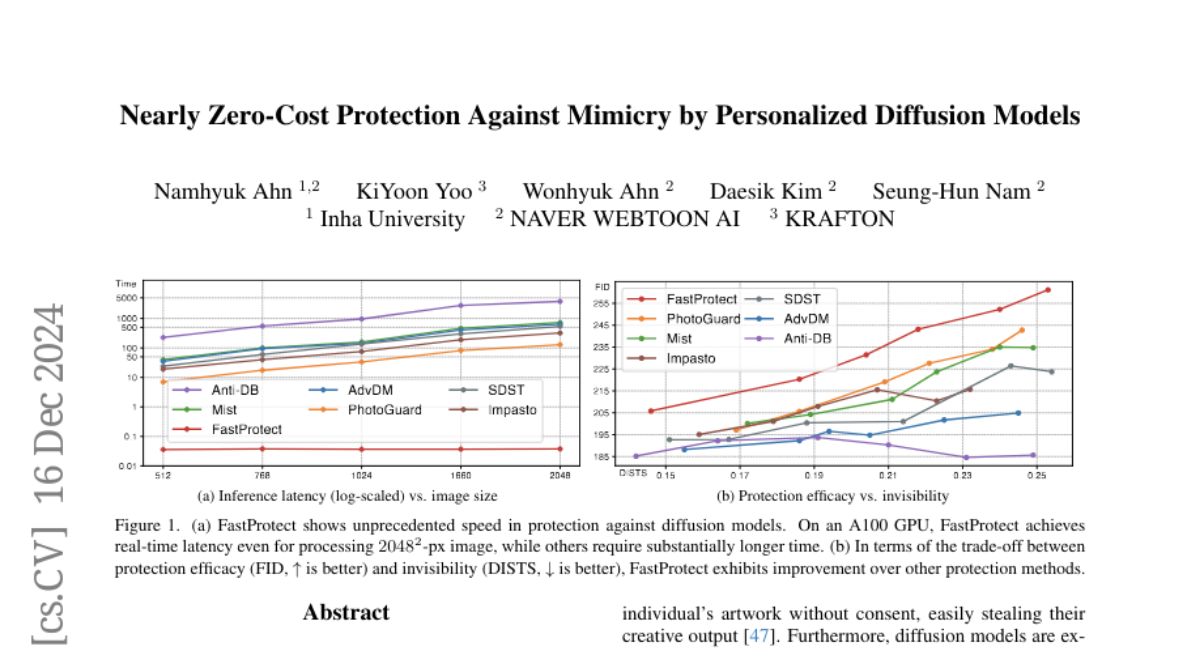
Защита от подражания с использованием персонализированных диффузионных моделей
Недавние достижения в моделях диффузии революционизируют генерацию изображений, но представляют собой риски неправильного использования, такие как воспроизведение художественных произведений или создание дипфейков. Существующие методы защиты изображений, хотя и эффективны, испытывают трудности с балансировкой эффективности защиты, невидимости и задержки, что ограничивает практическое применение. Мы представляем предварительное обучение с помехами для снижения задержки и предлагаем подход смешивания помех, который динамически адаптируется к входным изображениям для минимизации ухудшения производительности. Наша новая стратегия обучения вычисляет потерю защиты в нескольких пространствах признаков VAE, в то время как адаптивная целевая защита на этапе вывода повышает надежность и невидимость. Эксперименты показывают сопоставимую эффективность защиты с улучшенной невидимостью и значительно сокращенным временем вывода. Код и демонстрация доступны по адресу https://webtoon.github.io/impasto

