Факторизованная визуальная токенизация и генерация
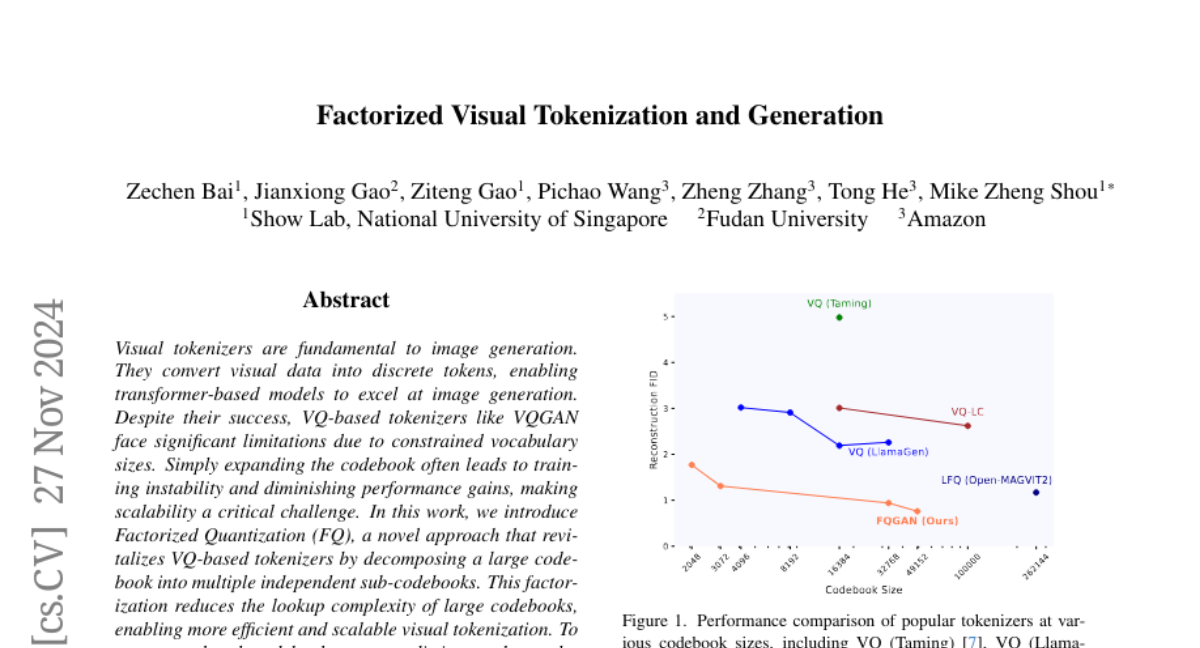
Визуальные токенизаторы являются фундаментальными для генерации изображений. Они преобразуют визуальные данные в дискретные токены, позволяя моделям на базе трансформеров превосходно справляться с генерацией изображений. Несмотря на их успех, токенизаторы на основе векторного квантования (VQ), такие как VQGAN, сталкиваются с значительными ограничениями из-за ограниченных размеров словаря. Простое расширение кодбука часто приводит к нестабильности обучения и уменьшению прироста производительности, что делает масштабируемость критической проблемой. В данной работе мы представляем Факторизованное Квантование (FQ), новый подход, который оживляет токенизаторы на основе VQ, разлагая большой кодбук на несколько независимых подкодбуков. Это разложение уменьшает сложность поиска в больших кодбуках, обеспечивая более эффективную и масштабируемую визуальную токенизацию. Для того чтобы каждый подкодбук захватывал различную и дополняющую информацию, мы предлагаем регуляризацию разъединения, которая явно снижает избыточность, способствуя разнообразию среди подкодбуков. Более того, мы интегрируем обучение представлений в процесс обучения, используя предобученные модели видения, такие как CLIP и DINO, для придания семантической насыщенности изучаемым представлениям. Эта конструкция обеспечивает, что наш токенизатор захватывает разнообразные семантические уровни, что приводит к более выразительным и разъединенным представлениям. Эксперименты показывают, что предложенная модель FQGAN значительно улучшает качество восстановления визуальных токенизаторов, достигая передовых результатов. Мы также демонстрируем, что этот токенизатор может быть эффективно адаптирован для автопрогрессивной генерации изображений. [Ссылка на проект](https://showlab.github.io/FQGAN)