Факторизованная визуальная токенизация и генерация
В последние годы визуальные токенизаторы стали краеугольным камнем в области генерации изображений, позволяя трансформерным моделям превосходно справляться с задачами создания изображений. Однако традиционные подходы, такие как VQGAN, сталкиваются с серьезными ограничениями при увеличении размера словаря. В этой статье мы исследуем новый метод, известный как Factorized Quantization (FQ), который решает эти проблемы, предлагая более эффективное и масштабируемое решение для визуальной токенизации.
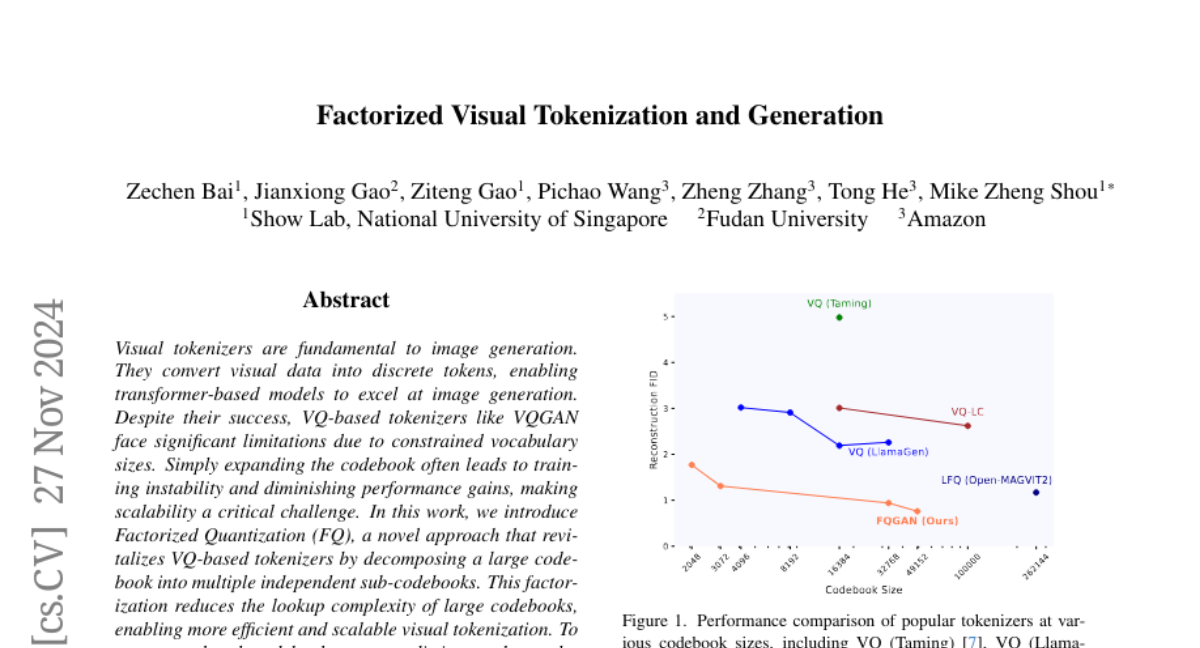
Визуальные токенизаторы преобразуют визуальные данные в дискретные токены, что позволяет использовать мощные трансформерные модели для генерации изображений. Качество токенизации напрямую влияет на точность и детализацию восстановления и генерации изображений. Традиционные VQ-токенизаторы, такие как VQGAN, используют структуру кодировщик-квантизатор-декодер, где квантизатор преобразует латентные признаки в дискретные токены с помощью векторной квантизации (VQ). Однако при увеличении размера словаря до 16,384 и выше возникают проблемы с нестабильностью обучения и насыщением производительности.
Проблемы и решения
Ограничения VQ-токенизаторов
Увеличение размера словаря в VQ-токенизаторах приводит к следующим проблемам:
- Нестабильность обучения: Большой словарь требует вычисления парных расстояний между выходами кодировщика и всеми записями словаря, что усложняет процесс выбора ближайшего кода.
- Насыщение производительности: Увеличение словаря не всегда приводит к улучшению качества восстановления изображений, часто наблюдается обратное.
Факторизованная Квантизация (FQ)
Для решения этих проблем мы предлагаем метод факторизованной квантизации (FQ), который разбивает большой словарь на несколько независимых подсловарей. Это позволяет:
- Уменьшить сложность поиска ближайшего кода.
- Улучшить стабильность и масштабируемость токенизации.
- Обеспечить каждому подсловарю возможность захватывать уникальную и дополнительную информацию.
Методология
Факторизованная Квантизация (FQ)
FQ разделяет словарь на ( k ) подсловарей, где каждый подсловарь обучается независимо:
- Кодировщик: Преобразует изображение в базовые признаки, которые затем адаптируются для каждого подсловари с помощью специальных адаптеров.
- Квантизатор: Каждый подсловарь квантизует свои признаки независимо.
- Декодер: Собирает квантизованные признаки из всех подсловарей для восстановления изображения.
Дизентанглирование
Для предотвращения избыточности и обеспечения уникальности каждого подсловари, мы вводим механизм регуляризации дизентанглирования: [ L_{\text{disentangle}} = \frac{1}{n} \sum_{i=1}^n (q_1^T q_2)^2 ] где ( q_1 ) и ( q_2 ) - квантизованные признаки из двух подсловарей, а ( n ) - количество сэмплов в батче. Это минимизирует скалярное произведение между кодами, поощряя ортогональность.
Обучение представлений
Для улучшения семантической значимости токенизатора мы интегрируем обучение представлений, используя предобученные модели, такие как CLIP и DINOv2:
- CLIP: Обеспечивает высокий уровень семантических признаков.
- DINOv2: Захватывает промежуточные визуальные детали.
Эти модели помогают токенизатору учиться на разных уровнях семантических представлений, что улучшает качество восстановления и генерации изображений.
Эксперименты
Настройки
Мы использовали стандартный бенчмарк ImageNet для обучения и оценки наших токенизаторов и моделей генерации. Наши эксперименты включали варианты FQGAN с двумя (FQGAN-Dual) и тремя (FQGAN-Triple) подсловари.
Результаты
- Восстановление изображений: FQGAN показал лучшие результаты по сравнению с существующими VQ-токенизаторами, достигая нового уровня в восстановлении изображений с использованием дискретных представлений.
- Генерация изображений: Адаптация FQGAN к авто-регрессивным моделям генерации показала конкурентоспособные результаты, особенно в сравнении с моделями, использующими схожие параметры.
Визуализация
Визуализация показала, что каждый подсловарь в FQGAN-Dual и FQGAN-Triple специализируется на различных аспектах изображения:
- Первый подсловарь фокусируется на низкоуровневых структурах (края, формы).
- Второй (и третий в FQGAN-Triple) подсловарь захватывает более высокий уровень семантики, включая текстуры и абстрактные аспекты.
Заключение
FQGAN предлагает новый подход к визуальной токенизации, который решает проблемы масштабируемости и стабильности, присущие традиционным VQ-токенизаторам. Использование факторизованной квантизации, дизентанглирования и обучения представлений позволяет создать более выразительные и семантически богатые представления изображений. Наши эксперименты показали, что FQGAN не только улучшает качество восстановления изображений, но и может быть эффективно интегрирован в задачи генерации изображений, предоставляя перспективы для дальнейших исследований в области визуальной токенизации и генерации.