Wonderland: Навигация по 3D-сценам из одного изображения
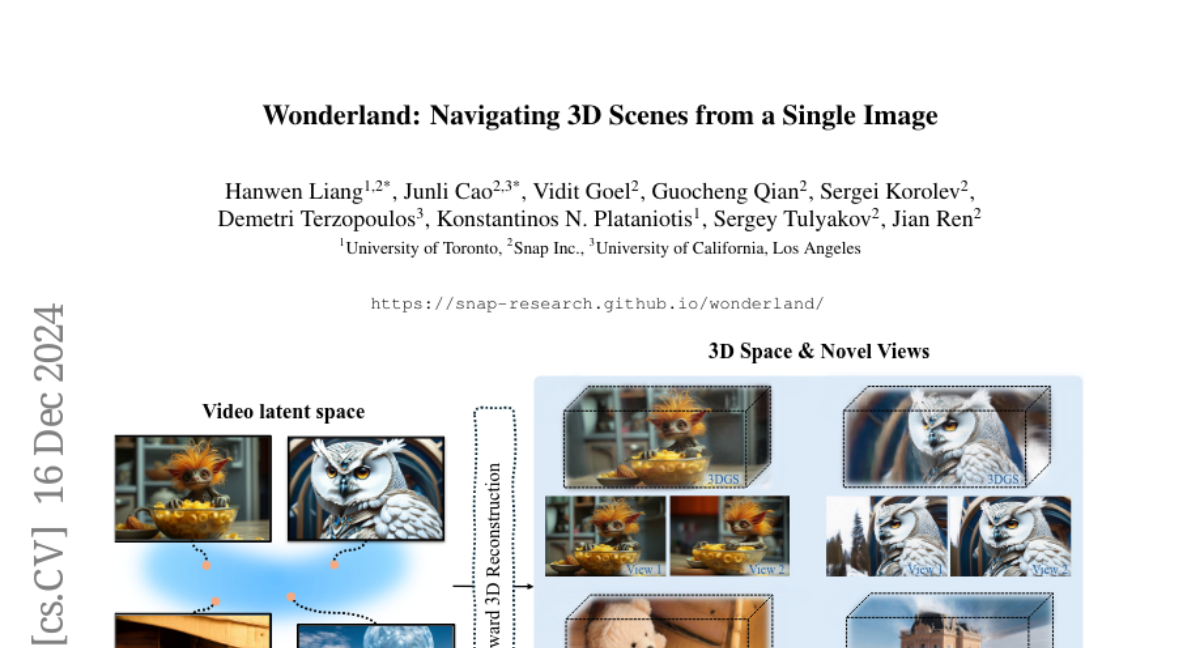
Эта работа касается сложного вопроса: как мы можем эффективно создавать высококачественные, масштабные 3D-сцены из одного произвольного изображения? Существующие методы сталкиваются с несколькими ограничениями, такими как необходимость в данных с нескольких точек зрения, продолжительная оптимизация для каждой сцены, низкое визуальное качество фонов и искаженные реконструкции в не видимых областях. Мы предлагаем новую схему, чтобы преодолеть эти ограничения. В частности, мы представляем масштабную модель реконструкции, которая использует латенты из модели диффузии видео для предсказания 3D-Гауссовских разбросов для сцен в прямом направлении. Модель диффузии видео разработана для создания видео, точно следуя указанным траекториям камеры, что позволяет ей генерировать сжатые видео-латенты, содержащие информацию с нескольких точек зрения, сохраняя при этом 3D-последовательность. Мы обучаем модель 3D-реконструкции работать в пространстве видео-латентов с помощью прогрессивной стратегии обучения, что позволяет эффективно генерировать высококачественные, масштабные и универсальные 3D-сцены. Обширные оценки на различных наборах данных демонстрируют, что наша модель значительно превосходит существующие методы генерации 3D-сцен с одного вида, особенно с изображениями из другой области. Впервые мы демонстрируем, что модель 3D-реконструкции может быть эффективно построена на основе латентного пространства модели диффузии для реализации эффективной генерации 3D-сцен.
