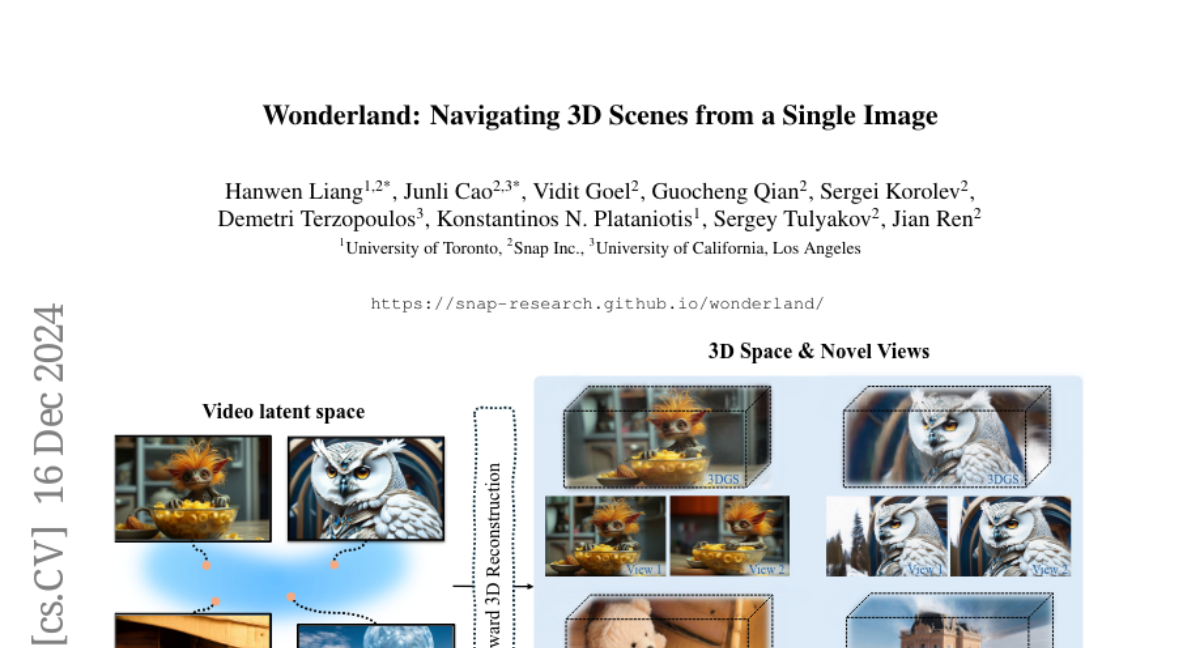
Wonderland: Навигация по 3D-сценам из одного изображения
Человечество обладает уникальной способностью воспринимать и представлять трехмерную информацию, глядя на одно изображение. Мы интуитивно оцениваем расстояния, распознаем формы и ментально представляем скрытые области. Однако воспроизвести этот когнитивный процесс с помощью алгоритмов машинного обучения крайне сложно, так как одно изображение предоставляет ограниченную информацию о размерах объектов и расстояниях между ними. В последние годы достижения в области представления сцен с помощью нейронных сетей, таких как Neural Radiance Fields (NeRF) и 3D Gaussian Splatting (3DGS), показывают многообещающие результаты, но сталкиваются с серьезными ограничениями, которые затрудняют их применение в широкомасштабных задачах.
Проблематика существующих методов
Существующие методы генерации 3D-сцен из одного изображения требуют многовидовых данных и затратного по времени процесса оптимизации для каждой сцены. Это приводит к низкому качеству визуализации фона и искаженным реконструкциям в невидимых областях. Некоторые исследования интегрируют генеративные приоритеты из моделей диффузии изображений для синтеза 3D-сцен из разреженных или одиночных изображений, но они также сталкиваются с проблемами 3D-консистентности в синтезе новых видов, такими как неправильная генерация скрытых областей и размытый фон.
Wonderland: Новый подход
В ответ на эти вызовы, мы представляем Wonderland — новую архитектуру, способную эффективно создавать высококачественные 3D-сцены из одного произвольного изображения. Wonderland использует большие модели реконструкции, которые применяют латентные представления из моделей диффузии видео для предсказания 3D Gaussian Splatting (3DGS) сцен в прямом режиме.
Основные компоненты Wonderland
-
Модель диффузии видео: Эта модель генерирует видео, следуя заданным траекториям камеры, создавая сжатые латенты, содержащие многовидовую информацию при сохранении 3D-консистентности.
-
Модель большой реконструкции (LaLRM): Эта модель преобразует латенты видео в 3DGS, что значительно ускоряет процесс реконструкции, позволяя получать высококачественные 3D-сцены.
-
Двухветвевое управление камерой: Мы внедрили новый механизм управления, который позволяет точно контролировать заданные траектории камеры, что дает возможность расширять одно изображение в многовидовую консистентную 3D-сцену.
Методология
3D Gaussian Splatting
3DGS представляет сцену как набор гауссовых точек, что обеспечивает быструю визуализацию и высокое качество результатов. В отличие от традиционных методов, которые могут требовать многовидовых данных, 3DGS может эффективно работать с латентными представлениями, что делает его идеальным для применения в Wonderland.
Генерация латентов видео
Модель диффузии видео генерирует латенты, которые содержат пространственно-временную информацию о сцене. Это достигается путем сжатия видео в латентное пространство с использованием 3D-VAE, что позволяет эффективно извлекать необходимые характеристики для 3D-реконструкции.
Двухветвевое управление камерой
Мы разработали двухветвевую архитектуру управления, которая включает в себя два набора токенов камеры, что позволяет модели более точно контролировать позы камеры. Это достигается путем использования 3D-свёрточных слоев для пространственно-временного сжатия.
Преимущества Wonderland
-
Высокая производительность: Wonderland значительно превосходит существующие методы генерации 3D-сцен из одиночного изображения, особенно в условиях нулевого обучения новых видов.
-
Улучшенная 3D-консистентность: Использование латентного пространства видео позволяет модели сохранять 3D-консистентность, что критически важно для качественной генерации сцен.
-
Скорость и эффективность: Процесс реконструкции сцен происходит в прямом режиме, что минимизирует затраты на вычисления и память, позволяя обрабатывать более широкий спектр 3D-сцен.
Эксперименты и результаты
Мы провели обширные эксперименты на различных наборах данных, таких как RealEstate10K, DL3DV, и Tanks-and-Temples. Результаты показывают, что Wonderland достигает состояния наилучшего искусства в генерации 3D-сцен из одиночного изображения, обеспечивая высокое качество визуализации и 3D-консистентность.
Качественные и количественные сравнения
В ходе экспериментов мы сравнили Wonderland с несколькими существующими методами, такими как MotionCtrl и ViewCrafter. Wonderland показал значительно лучшие результаты по метрикам качества изображения, включая FID, PSNR и SSIM.
Заключение
Wonderland представляет собой значительный шаг вперед в области генерации 3D-сцен из одиночных изображений. Комбинируя мощные модели диффузии видео с современными методами 3D-реконструкции, мы создали эффективный и мощный инструмент для синтеза 3D-сцен, который может быть использован в различных приложениях, от виртуальной реальности до компьютерной графики. В будущем мы планируем расширить возможности Wonderland для работы с динамическими сценами и улучшить его производительность.
Таким образом, Wonderland открывает новые горизонты в области 3D-визуализации, предлагая решения для задач, которые ранее считались слишком сложными для алгоритмов машинного обучения.