VISTA: Улучшение понимания видео длительного и высокого разрешения с помощью пространственно-временной аугментации
Современные достижения в области больших языковых моделей (LLMs) и больших мультимодальных моделей (LMMs) привели к значительным изменениям в задачах понимания видео. Традиционно понимание видео полагалось на обучение моделей, специфичных для задач, с использованием домен-специфичных наборов данных, таких как распознавание действий или видеопоиск. Однако с развитием LMMs появилась возможность обрабатывать видео и решать разнообразные задачи с помощью единой модели. Тем не менее, большинство текущих LMMs оптимизированы для понимания коротких и низкоразрешающих видео, что создает значительные проблемы при работе с длительными или высокоразрешающими видео.
Проблемы существующих моделей
Существующие открытые наборы данных для обучения LMMs часто имеют ограничения, такие как низкое разрешение или короткая продолжительность видео. Например, набор данных VideoChat2 собирает видео из множества доменов, но в основном содержит короткие видео. FineVideo предлагает разнообразные видео, но ограничивается разрешением 360p. Это создает нехватку высококачественных наборов данных для видео с длительной продолжительностью и высоким разрешением, что затрудняет дальнейшее развитие моделей.
VISTA: Новый подход
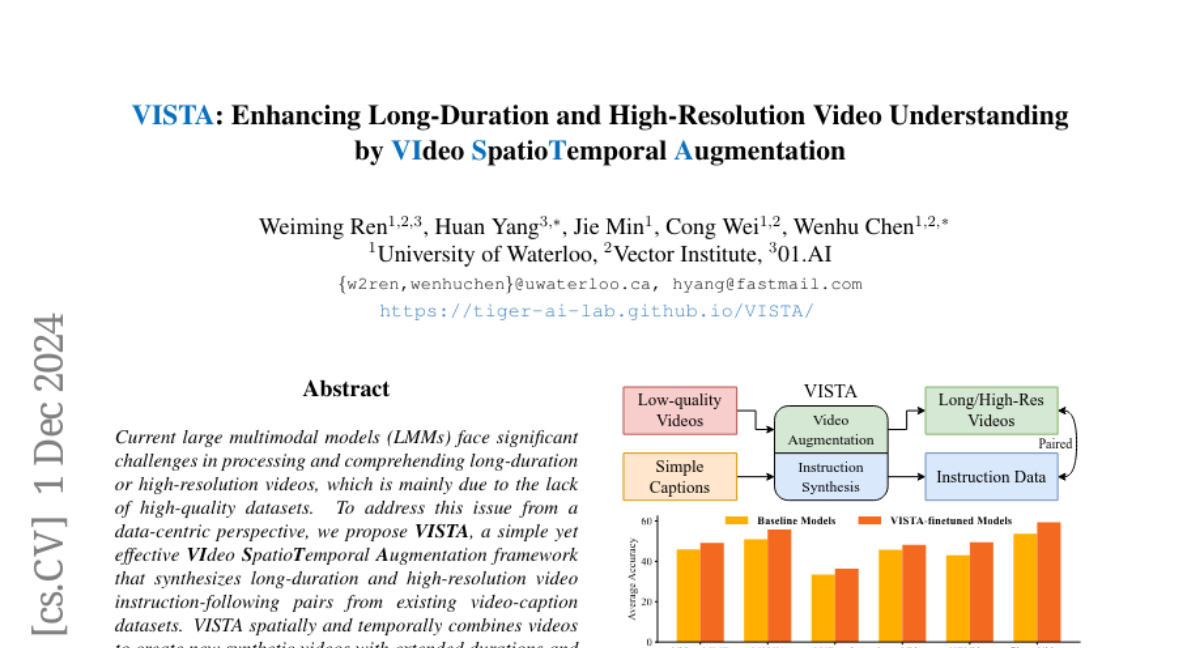
Чтобы преодолеть эти проблемы, мы предлагаем VISTA, простую, но эффективную систему аугментации видео, которая синтезирует пары видео и инструкций из существующих наборов данных с подписями к видео. VISTA использует пространственно-временные методы комбинирования видео для создания новых синтетических видео с увеличенной продолжительностью и улучшенным разрешением. Затем мы генерируем пары вопросов и ответов, относящиеся к этим новым видео.
Структура VISTA
VISTA включает в себя несколько методов аугментации видео и набор данных VISTA-400K, который направлен на улучшение понимания видео длительной и высокой разрешающей способности. В результате дообучения различных LMMs на нашем наборе данных мы наблюдаем среднее улучшение на 3.3% по четырем сложным бенчмаркам для понимания длинных видео.
Методы аугментации видео
VISTA включает в себя семь различных методов аугментации видео, каждый из которых нацелен на улучшение понимания видео различными способами.
1. Долгое видео с подписями и QA
Первый метод заключается в синтезе длинных видео путем временной конкатенации нескольких коротких клипов из одного и того же источника. Мы генерируем два типа инструкций:
- Долгое видео с подписями: Генерируем более длинную подпись, описывающую все видео.
- QA по событиям: Генерируем вопросы о порядке событий на основе подписей коротких клипов.
2. QA "игла в стоге сена" (NIAH)
Данный метод оценивает способность LMMs находить информацию в длинных видео. Мы создаем несколько вариантов NIAH, включая:
- Темпоральная NIAH: Вставляем короткий клип в более длинное видео, создавая "темпоральную иглу".
- Две иглы NIAH: Разделяем короткое видео на две части и вставляем их в разные временные метки.
- Пространственная NIAH: Накладываем короткое видео на высокоразрешающее видео и задаем вопросы о содержимом.
3. QA по высокоразрешающему видео
Мы создаем высокоразрешающие видео, комбинируя несколько низкоразрешающих клипов в сетку. Это позволяет LMMs изучать детали в высоком разрешении, требуя от них точно интерпретировать содержание в конкретной ячейке сетки.
4. Объединение пространственной и временной NIAH
Этот метод объединяет пространственные и временные аспекты, помещая короткое низкоразрешающее видео в длинное высокоразрешающее видео, чтобы LMMs могли понять контент на обоих уровнях.
Набор данных VISTA-400K
VISTA-400K состоит из около 400,000 записей, каждая из которых включает длинное видео продолжительностью более 30 секунд и высокое разрешение не менее 960p. Набор данных был создан с использованием существующих публичных видеоподписей, что делает его полностью открытым и масштабируемым.
Оценка: HRVideoBench
Для оценки эффективности VISTA мы представляем новый бенчмарк HRVideoBench, который нацелен на понимание высокоразрешающих видео. Он включает 200 вопросов, охватывающих 10 типов видео и задач, связанных с объектами и действиями.
Экспериментальные результаты
Мы провели обширные эксперименты, чтобы оценить эффективность VISTA-400K на различных бенчмарках для понимания видео. Результаты показывают, что модели, дообученные на нашем наборе данных, демонстрируют значительное улучшение на всех тестах.
Долгое видео
На бенчмарках для понимания длинных видео, таких как Video-MME и MLVU, модели, дообученные на VISTA-400K, показывают улучшение на 3.3% в среднем. Это улучшение особенно заметно на средних и длинных вопросах, что подтверждает эффективность нашего подхода.
Высокое разрешение
На новом бенчмарке HRVideoBench, модели показывают прирост производительности на 6.5% после дообучения. Это демонстрирует, что VISTA действительно улучшает понимание деталей в высокоразрешающих видео.
Краткие видео
Мы также проверили эффективность нашего метода на бенчмарках для кратких видео. Все модели, дообученные на VISTA-400K, показали улучшение на MVBench и NExT-QA, что подтверждает универсальность нашего подхода.
Заключение
VISTA представляет собой мощный инструмент для улучшения понимания видео длительного и высокого разрешения, предоставляя синтетические данные, которые значительно усиливают возможности LMMs. Наша работа подчеркивает важность создания высококачественных наборов данных для обучения и тестирования современных моделей, а также открывает новые направления для будущих исследований в области видеоанализа.